Dealing With Python Apps
The punch story with python is an old one. We implemented an elasticsearch aggregator tool in the Brad release (now deprecated), we also leveraged the elasticsearch curator application that we provide as a deployable administrative service in the Craig release. More importantly, we decided to fully support pyspark and to make python a first-class citizen language so that we and our users are well equipped to provide generic or custom processing nodes.
The way we packaged python was based on our own tooling. For packaging pyspark apps, we designed something similar to Eran Kampf’s proposal. We still use Eran’s scheme to package not just pyspark but also plain python pipelines. Not to mention the arrival of airflow in the punch, itself doing something similar.
For obvious reasons, we really need a stable, robust strategy to package python applications. The punch is a clustered, distributed data platform particularly well suited for on-premise deployments, with stringent security and networking constraints. This blog explains what we decided to do starting in our next release (planned before the end of this year).
Python Packaging Landscape
As stated by the Python Package Authority (PyPa), the traditional way of packaging python application is to make use of a number of tools: sdist, wheels, and setuptools. These tools are great for packaging pure python applications, i.e. applications with no external non-python dependencies such as statically linked libraries. For more complex applications, these tools are too limited, and it quickly becomes a nightmare.
In the data science field, where performance matters, python modules (Numpy, scikit-learn, …) heavily rely on such external dependencies. Because no clear and standard solution was mature, many famous big tech companies (Facebook, Linkedin, Spotify, Twitter, etc…) all developed their own packaging tools to deal with it the right way. Here are some well-known solutions:
- shiv by LinkedIn
- PyInstaller and PythonFreezer, used a lot in the gaming industry
- Conda by Anaconda, used mainly for data science
- dh-virtualenv by Spotify
- XARS by Facebook
All these solutions share the same idea to package the whole python application together with its dependencies into a single executable file ready to be deployed and executed on the target environment.
After some thoughts and experiments, we have selected PEX to do the job. Here is why.
PEX Overview
PEX (Python Executable) idea is to bundle all the required application dependencies in a zip archive, much like uber jars are used in the java ecosystem. PEX specifications can be found in the PEP-440 and PEP-441 draft papers.
A PEX file is thus a single zip archive that contains the application code and its dependencies which can be executed as a binary file. PEX also provides a client application (cli) to automate the various steps for generating the final archive.
The benefits are as expected:
- being able to package a whole application with its required dependencies without the need of executing a `pip install -r dependencies.txt` before you can actually run it
- reducing the complexity in our CI/CD pipeline for packaging python application on an on-premise environment
- zero-risk of polluting your system python environment
As a general note, PEX is not here to replace containers, in contrary, the coupling of PEX and containers makes as a whole a cleaner solution for delivering python application.
Why PEX ?
Several reasons led us to choose PEX. First PEX is already used in production for data science use-cases. As explained by Criteo, playing with solutions such as virtual-environment or even Conda variants is inefficient/dangerous. The so-called relocation, i.e. the ability to not depend on specific installation paths, is not a safe option. As documented on the virtual-environment documentation:

A virtual-env is not something that you can move around easily from one node to another. You do not want to recreate the virtual environment everywhere either, as it is not a scalable solution.
Coming back to PEX, it relies on the PyPi / PyPa to resolve and fetch module dependencies. PyPi and PyPa are the java equivalent of the maven central jar repository : the standard and most complete source of official online modules. In contrast, Conda depends on its own dependency servers, hence the risk of missing the latest modules.
What is really interesting with PEX is it’s spark support. As of 2019, Pyspark supports PEX natively This is an excellent news as you can just submit a PEX archive containing your spark application and your application dependencies. Spark driver will take the role of ensuring that each worker on your spark cluster has the required dependencies.
At last but not least, PEX has a rich documentation and provides cross linux-compatiblity for PEX executable built on a linux distribution.
On the downside, PEX incurs a startup latency that can be annoying for some applications, such as cli tools for example. Here are measurements performed by Facebook in comparing their own solution with PEX. Notice the additional latency.

This latency is, to us, not an issue for data science and big data use cases.
PEX in Punch
To make it very concrete, here is how we use PEX. What is described next will be the supported strategy starting at the punch Dave release.
Punch On-The-Shelf Services
Let us start with a simple python based punch service. I.e. not a spark one. One that you can select and deploy by configuration. An example is the elasticsearch curator-based housekeeping service. This service is a small python apps that automatically cleans and/or moves Elasticsearch indices from hot to cold/frozen storage. You can request the punch to execute that service periodically, i.e. typically every day.
As a punch user you do not care on how that service is executed. We explain this simply to illustrate the internal use of PEX. Here is the idea : after installing a punch, these small services are preinstalled as PEX archive on each cluster node who are subject to run that service.
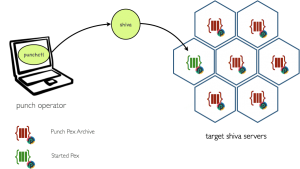
Shiva is a sort of extra lightweight job orchestrator that we use to run such service in a resilient and distributed way. Using PEX, it is safe and easy to install many small apps on every server and have Shiva schedule as you like. If you were to use Kubernetes or any other orchestrator, the idea would be similar.
Punch PySpark Application
Consider now a more interesting example. You design a Pyspark job using the punch machine learning editor. By doing that you generate a (py)spark apps that only relies on the punch ready-to-use nodes. After submitting your job to the Punch, the spark driver will take care of distributing your application source code and it’s dependencies to the spark workers, as shown in the diagram below:
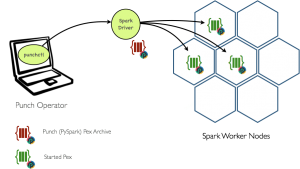
Once your job completes, the PEX archive will get automatically cleaned-up. In other words, worker nodes of your spark cluster are not polluted with unwanted dependencies… which in turn guarantees a more robust system.
Note that the only requirement you need is to equip your servers with a standard python 3 environment.
User PySpark Application
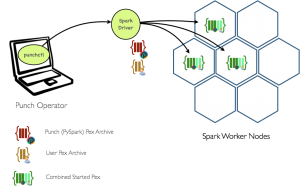
Say now you want to add our own python processing node to the punch. There are many excellent reasons to do that. Checkout this previous blog. With PEX, doing that will be easier (starting at Dave release). The punch will equip your development environment with a tool to easily generate a PEX archive with your own code together with its dependencies.
Once submitted to the punch, the punch PEX plus your own PEX are combined and executed again through Spark as illustrated below:
Plain Python Applications
It is worth noticing that with PEX and the punch services, you can also deploy standard python applications in a very controlled way. This is also very useful to deploy, for instance, a GPU capable python application on a dedicated server.
Conclusions
Python and PEX rock! Thanks to Criteo for their their excellent blog on that topic.
Jonathan Yue Chun & Dimitri Tombroff



0 Comments