Our team is developing a service called Thalc to help customers estimate the carbon costs of their infrastructure or applications.
There are many use cases, of course, for such carbon estimation services. Most companies must now precisely estimate and forecast the carbon cost of their data centers, cloud applications, human resources, or other activities. This problem is vast and challenging, mainly because it requires correlating many different data types.
In our case, we started focusing on collecting power consumption measures from hypervisors and data centers, forwarding that data to a central platform where we process it in various ways. First, we enrich it with contextual data coming from local energy providers. An example is electricity maps. Second, we collaborate with Kabaun (https://www.kabaun.com/en), which provides a service to compute and estimate carbon costs easily.
Here is a straightforward architectural view of Thalc:

We know Thalc will eventually be deployed on private clouds or on-premise platforms for stringent confidentiality and sovereign constraints. We, therefore, decided to develop it on top of Kubernetes. Kubernetes is widely used, particularly in our company, and most importantly, it is available on every public cloud, making it simple to develop and test our application. Even better, our company provides us with a complete Kubernetes analytics stack (called Kast) that allows us to deploy not only Kubernetes but also the required security and data components onto on-premise platforms easily and quickly.
Thalc is a multifaceted project and has many goals. The main one is helping our customers evaluate their carbon footprint and build a relevant strategy based on measures and predictions. But, as we are engaging in a new upcoming market, we also wanted to shorten the time-to-market needed to deliver a fully secured and scalable solution that can fit the diversity of modern infrastructures.
Kubernetes seems ideal. It protects us from a particular cloud provider vendor-locking, and whatever you need to implement, there is always a solution with Kubernetes. Right?
Right, but with Kubernetes, we still must identify an easy way to implement our data pipelines. Using managed services and serverless/FaaS capabilities offered by GCP would be simple and easy. How do you do that on Kubernetes?
Here comes Punch
We decided to try out Punch. Punch is a cloud-native solution that facilitates the deployments of functions into various ETL-like engines. It installs on Kubernetes easily using Helm, and there you go; you can design the data application you need.
Here is the exciting part; the complete application is illustrated next:
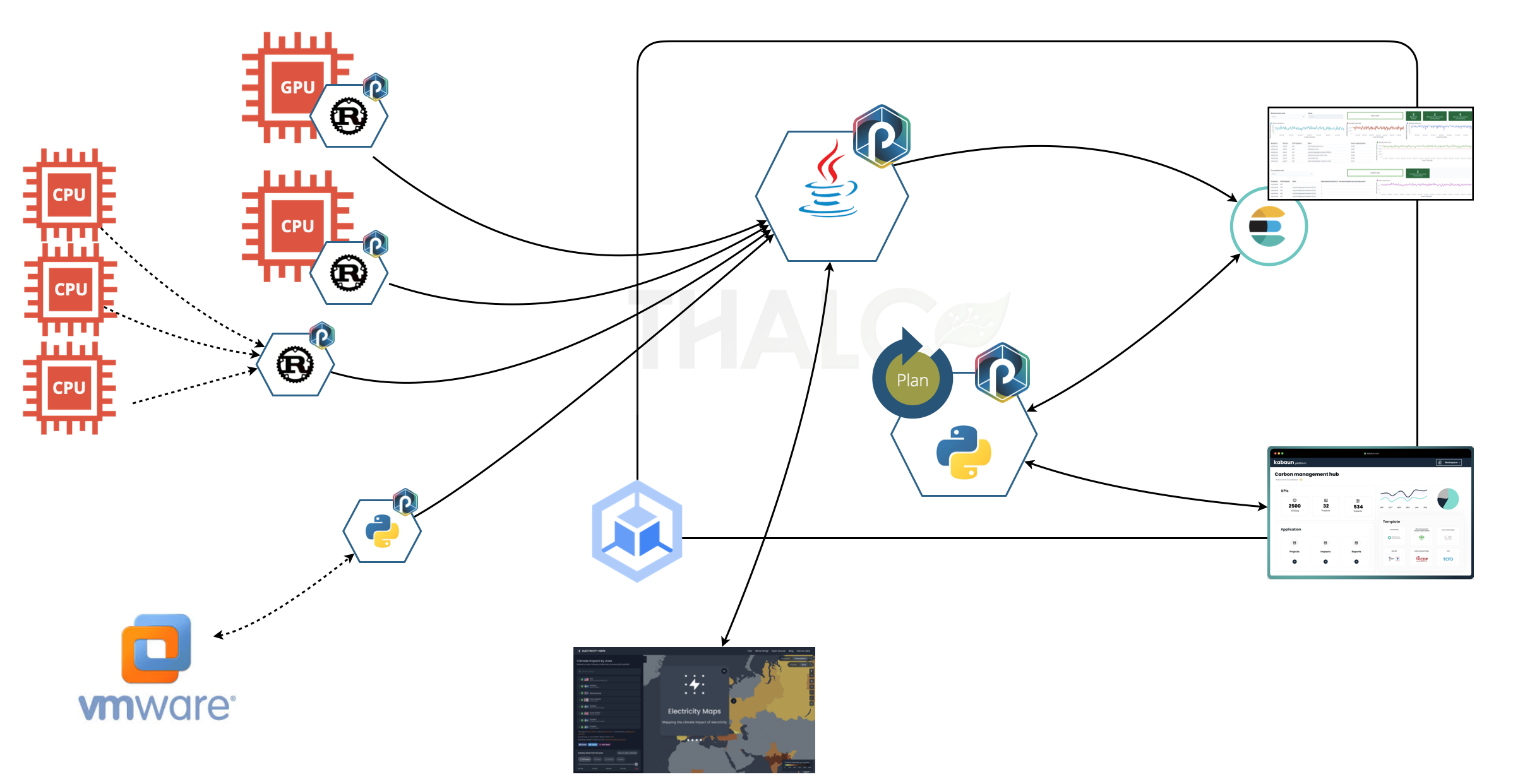
Thalc is composed of four types of Punch pipelines. They call that punchline.
First on remote data centers :
- (Rust) punchlines are deployed directly into the external observed systems to grab server consumption measures. They forward (directly or through an intermediate gateway. That gateway is yet another punchline.
- A Python punchline interrogates VMware APIs to get the equivalent consumption data for a complete VMware cluster. Why a Python punchline? Because VMware provides a Python library to do that. It was easy to add a custom source to the existing Python punchline, et voilà ! no need to develop yet another tiny application on our side. We benefit from the Python punchline on the shelve functions and sinks to forward the data to our central platform.
Next on a GCP/GKE managed Kubernetes:
- We use a single (java) punchline to receive all these data using an HTTP source. That punchline enriches that data on the fly with Electricity data fetched using an HTTP poller source from a remote public service, then ingests that data into Elasticsearch. That was coded using about 15 lines of Punch punchlang language, a very compact language designed to manipulate streaming data.
- Lastly, we need to schedule a periodic batch application that reads the (last hour or so) of Elasticsearch data, perform some calculation, and forward it to our Kabaun instance using Kabaun REST API. This is easily implemented using a Punch plan: a sort of cron scheduler that generates and runs a new punchline whenever required. The plan automatically fills the generated punchline with the (from, to) timestamps to consume the latest data slice. As simple as that.
There are countless ways to implement this on top of Kubernetes. You can build your own FaaS/Serverless design with Knative or ship your applications as containers, scheduled with an Argo workflow. You can even run only your containers using the GCP runtime to avoid Kubernetes altogether. All these work without a doubt, but first, we are not interested in container workflows and YAML files; we prefer to start directly with functions and ready-to-use connectors.
Second, we were surprised to realize that implementing a plan with Kubernetes or workflow managers such as Argo is difficult. You need every slice of data to be ultimately processed. Data (slice) losses are not acceptable, of course. Guaranteeing this requires a sort of cursor saving. If a plan crashes because of a worker crash, it must restart elsewhere from the last slice of consumed data. The punch plan deals with that nicely. It is not a concern to us.
Collateral Gains
What I just explained made us gain quite some time. Thlac is now running on a secured online GKE, and we are focused on adding use cases.
By using Punch, we are also going to benefit from many additional features that are all simple but essential:
- Configuration Management: Punch stores the pipeline configurations for us. Simple UIs let you visualize and manage these.
- Device management: Punch automatically detects data sent by new incoming agents (devices or gateways) and provides us with REST API and UIs to manage these. You can see what business function runs on which remote agent and update it by providing (say) a new WebAssembly function. Device management is essential for applications like Thalc, which aggregates data from various sources.
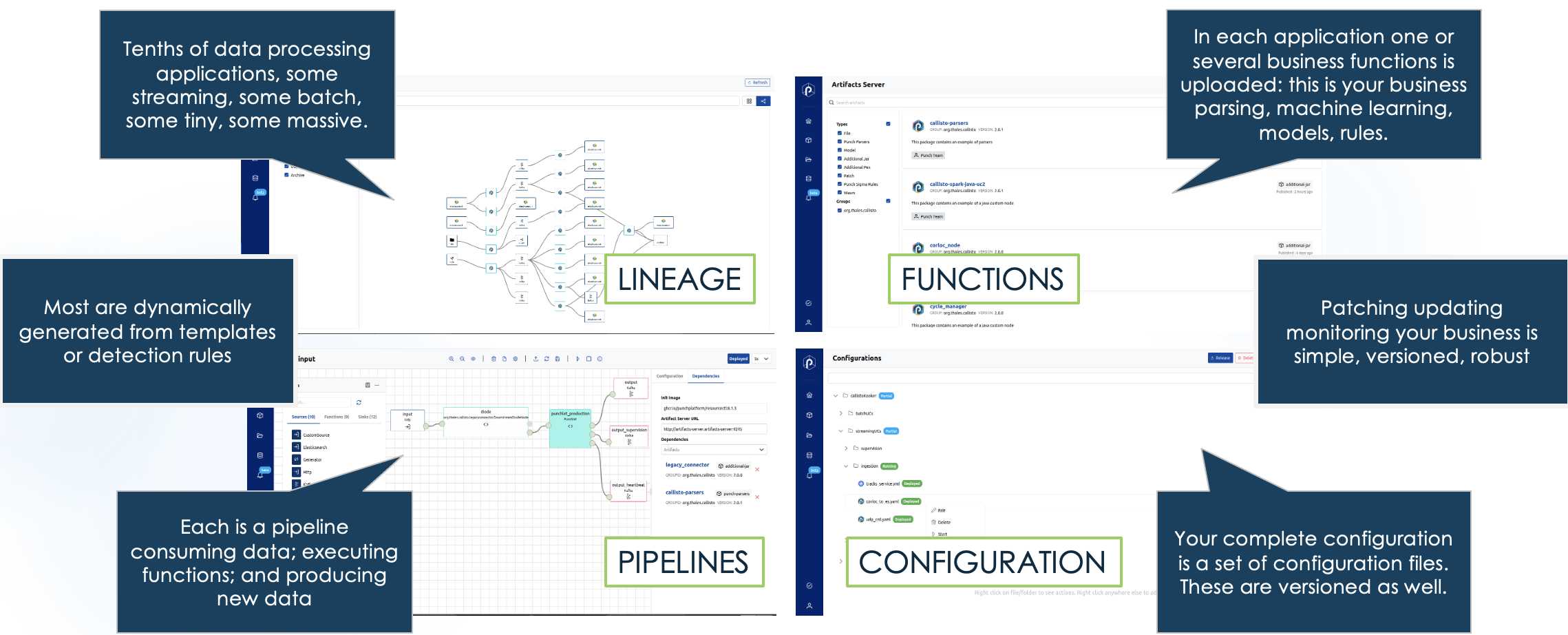
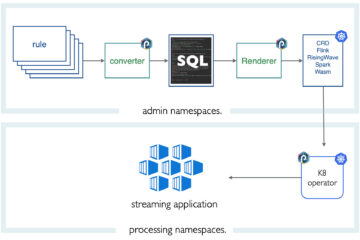
- Data lineage: having Rust, Python, Java, Spark, Flink, (and soon RisingWave) pipeline engines all accepting a SQL-like ETL format is mighty. Punch provides a table view to track data lineage from sources to the various backends. You understand your complete end-to-end architecture on a simple view.
Here is a sample view of the Punch administrative board (courtesy of Punch docs):
Is it Heavy?
A last point worth noticing: Punch installs itself on an empty Kubernetes using Helm. It comprises a REST server, a Kubernetes operator, and a UI backend. It only requires a S3 storage of some sort. This small footprint avoids the burden of installing additional databases or dependencies.
In the end, simplicity is what we prefer in the Punch.

1 Comment
Smart data FaaS with WebAssembly & Rust · September 18, 2023 at 09:23
[…] first use case, Thalc, consists of collecting electricity measures from various data centers and forwarding the data to a […]