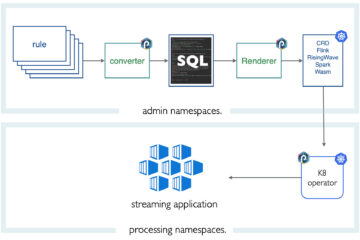
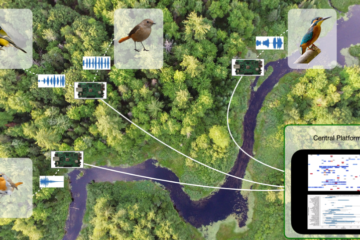
Architecture
Rust, WebAssembly, TensorFlow, and RISC-V: a powerful cocktail for edge AI.
In this first blog of a new series, we pursue our bird song detection prototype by setting up a complete working solution using Rust, TensorFlow, WebAssembly, and RISC-V. We will explain why we explore such Read more…