Overview
Before reading this blog, we strongly encourage you to read this very interesting blog from sekoia. They explain why they decided to leverage Sigma rules instead of other formats (namely STIX) to deal with complex correlation patterns.
Here is a simple example: say you want to generate alerts if you detect 10 failed user login attempts in 3 minutes followed by one successful login. To express this with Sigma, you first define two simple rules: one to detect failed logins and one to detect successful logins. Next, you define a (so-called event count) rule to detect the repetition of 10 failed logins within 3 minutes. And last, you define a (so-called temporal) rule to express the sequence of failed logins followed by a successful login. Here is a schematic view of all four rules.
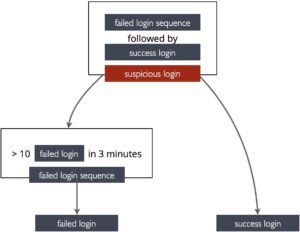
This looks complex, but it is powerful. The interesting question is how to generate an application from such a rule set to do the job. Many so-called Sigma rule converters are available that transform a rule to a target-specific technology: IBM qradar, Splunk, SQL, Elastalert, etc. However, very few are capable of dealing with complex correlation rule sets. In part because the Sigma specification is incomplete and today’s PySigma converter tool is cumbersome and was not designed properly to deal with these. Sekoia pioneered an implementation. They also extended Sigma rules with a few extensions useful for their use cases. Another very interesting work explores executing sigma rules at scale.
In this blog, we present our implementation. We focused on implementing a rule converter to transform arbitrarily complex Sigma rules into Streaming SQL applications. More precisely, our goal is twofold:
- Execute rule detections in streaming pipelines instead of batch applications: the rationale here is to replace many periodic batch applications (or requests) that put under stress the backend database used to store the indexed logs with lightweight streaming applications. More on this below.
- Take benefit of the modern streaming SQL technologies available: Apache Flink, Apache Spark, or RisingWave. This makes it straightforward to execute these rules at scale, requiring no code.
Streaming SQL Generation
Let us start explaining how the streaming SQL is generated from a rule set. Here is an example of the generated SQL. This SQL is a Flink SQL variant. Each technology introduces its dialect and many subtle primitives to work with columns, JSON, CSV, or other formats. Consequently, our rule converter has been designed to generate specific variants. For instance, in the generated code shown next, you see the use of flink JSON_VALUE primitive:
CREATE VIEW sigma_1da8ce0b_855d_4004_8860_7d64d42063b1 AS (
SELECT
'Login failed' AS `title_rule`,
'1da8ce0b-855d-4004-8860-7d64d42063b1' AS `id_rule`,
PROCTIME() AS `rule_record_time`,
JSON_VALUE(`data`, '$.source.address') AS `source.address`
FROM kafkaTable
WHERE (JSON_VALUE(`data`, '$.http.response.status_code')='401' AND JSON_VALUE(`data`, '$.url.original') LIKE '%authentication%')
);
CREATE VIEW sigma_0e95725d_7320_415d_80f7_004da920fc27 AS (
SELECT
'Login failed sequence' AS `title_rule`,
'0e95725d-7320-415d-80f7-004da920fc27' AS `id_rule`,
PROCTIME() AS `rule_record_time`,
*
FROM (
SELECT `source.address`,
count(*) OVER w AS event_count,
CAST(MIN(rule_record_time) OVER w AS TIMESTAMP) AS `window_start`,
CAST(MAX(rule_record_time) OVER w AS TIMESTAMP) AS `window_end`
FROM sigma_1da8ce0b_855d_4004_8860_7d64d42063b1
WINDOW w AS (
PARTITION BY `source.address`
ORDER BY `rule_record_time`
RANGE BETWEEN INTERVAL '00:03:00' HOUR TO SECOND PRECEDING AND CURRENT ROW
)
)
WHERE `event_count` > 10
);
CREATE VIEW sigma_1da8ce0b_855d_4004_8860_7d64d42063b2 AS (
SELECT
'login success' AS `title_rule`,
'1da8ce0b-855d-4004-8860-7d64d42063b2' AS `id_rule`,
PROCTIME() AS `rule_record_time`,
JSON_VALUE(`data`, '$.source.address') AS `source.address`
FROM kafkaTable
WHERE (JSON_VALUE(`data`, '$.http.response.status_code')='200' AND JSON_VALUE(`data`, '$.url.original') LIKE '%authentication%')
);
CREATE VIEW temp_0e95725d_7320_415d_80f7_004da920fc20 AS (
SELECT `id_rule`, `rule_record_time`, `source.address` FROM sigma_0e95725d_7320_415d_80f7_004da920fc27
UNION ALL
SELECT `id_rule`, `rule_record_time`, `source.address` FROM sigma_1da8ce0b_855d_4004_8860_7d64d42063b2
);
CREATE VIEW sigma_0e95725d_7320_415d_80f7_004da920fc20 AS (
SELECT
'Suspicious login' AS `title_rule`,
'0e95725d-7320-415d-80f7-004da920fc20' AS `id_rule`,
PROCTIME() AS `rule_record_time`,
*
FROM temp_0e95725d_7320_415d_80f7_004da920fc20
MATCH_RECOGNIZE (
PARTITION BY `source.address`
ORDER BY `rule_record_time`
MEASURES
R0.rule_record_time AS `window_start`,
R1.rule_record_time AS `window_end`
ONE ROW PER MATCH
AFTER MATCH SKIP PAST LAST ROW
PATTERN (R0 R1)
WITHIN INTERVAL '00:01:00' HOUR TO SECOND
DEFINE
R0 AS R0.id_rule='0e95725d-7320-415d-80f7-004da920fc27',
R1 AS R1.id_rule='1da8ce0b-855d-4004-8860-7d64d42063b2'
)
);
CREATE VIEW sigma_alerts AS (
SELECT `id_rule`, `rule_record_time`
FROM sigma_0e95725d_7320_415d_80f7_004da920fc20
);Looking at this, you should immediately conclude that going for SQL by hand is impossible. That is all the benefit of the Sigma (or similar) rule approach to generate complex code from human-understandable rules. Many additional issues are not explained here. Let us only mention the topic of dealing with the input data schema. In log management and cybersecurity platforms, schemas such as the Elastic Common Schema are defined. In one way or another, the generated SQL must know that schema to allow all the required SQL operations to properly work on typed columns. Think of GROUP BY clauses for example.
Let us now address the issue of running these statements.
Executing Rules
How do you execute such SQL statements? You may have noticed an inputTable reference in the SQL above. That input table will provide the input data, in our case, parsed logs. All we have to do is to declare one that matches our target platform architecture. It could be a Kafka topic, a Nats topic, an azure event hub broker, etc.. Applying the same logic to the output table will generate an SQL streaming pipeline that you then need to submit for execution in some way.
Adding adequate input and output tables is not the concern of the Sigma rule convertor; we defer it to a renderer application that provides the required templating mechanism to accommodate the target architecture. Here is how this is achieved on the Punch. Punch provides declarative pipelines, a Kubernetes operator, and various runtime engines (Spark, Python, Java, Rust/Wasm, Flink), so you have the choice here. Here is the typical architecture.
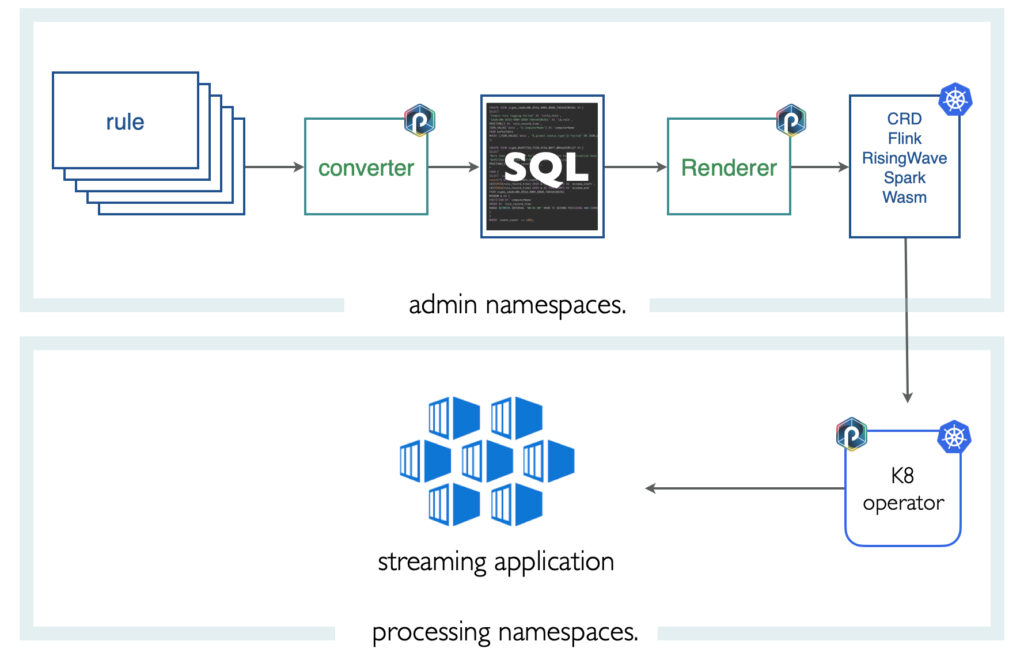
A 100% Rust-Wasm powered detection platform
We envision a data processing platform that provides such detection capabilities on top of performant, frugal, and safe processing engines. We are currently working on adding RisingWave as an additional backend SQL streaming engine.
RisingWave is entirely written in Rust. It provides only a Postgres-compatible SQL (unlike Spark and Flink, which provide many other APIs). This elegant technology can be deployed using little resources (on small or edge platforms) yet provides the sophisticated exactly-once/distributed clustered architecture should you need to run complex stateful queries on large datasets. Another technology we develop is a lightweight function engine dedicated to running Rust and Web Assembly functions. This engine, called Reef, will help us deploy detection rules on edge devices or central platforms shipped as Web Assembly functions. One of the many reasons to do this is to help customers design smart, frugal platforms that detect and filter interesting events efficiently and possibly at the edge to avoid unnecessary data transport.
The business space for such smart data platforms is vast. It is worth noting that data schemas in other business verticals (IoT, electronic warfare, fraud detection, industry) are usually well-defined and simpler than in log management and cybersecurity applications. Log management is known to be a hard use case because of the poor data structures of incoming logs. Applying the approach described in this blog to these other business verticals is, therefore, highly promising.
Stay tuned for our next blogs on these interesting developments.



0 Comments