Among many other useful things, big data platforms lets you design data pipeline,
fetching or receiving data from one side, applying some transformations, then pushing the resulting data
further. If you run a punchplatform, you are likely to do that to collect then parse your data into Elasticsearch, in turn visualizing it using Kibana. Here is a typical example you get in minutes using the standalone punchplatform.
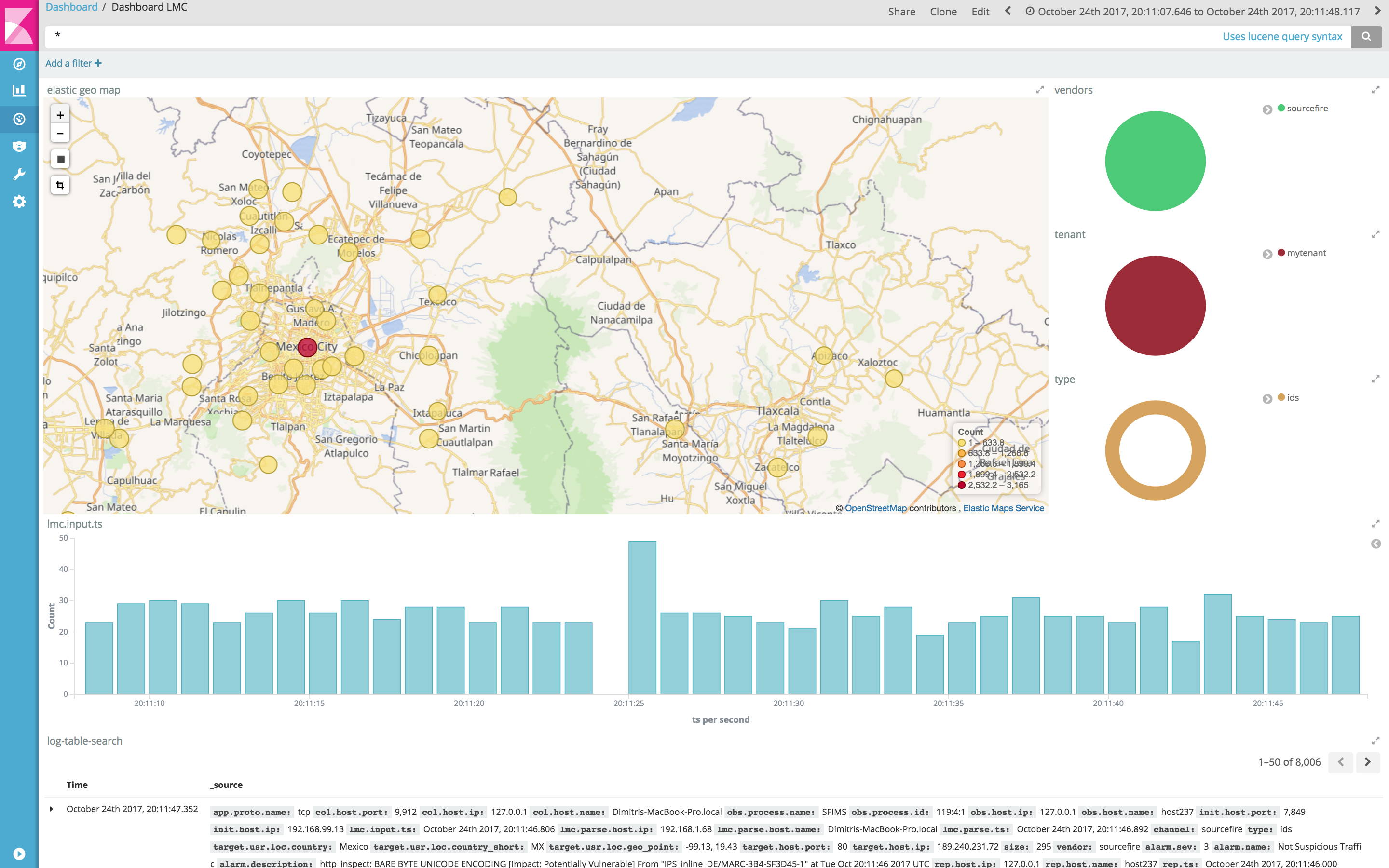
Setting up pipelines is nothing new of course, what is new is the many new ways
to do this : Storm, Spark, KakaStream/KafkaConnect processors, themselves orchestrated
by schedulers or workflow tools such as apache Nifi, to name a few.
Of course, the best is to code nothing. Good platforms lets you simply configure the pipelines
and go production straight ahead. The punchplatform lets you do that for native,
Spark and Storm applications.
We actually started doing this leveraging Storm concepts. Why ? because it has a powerful yet
simple to understand pipeline pattern : the so-called topologies.
In there spouts are data fetchers, bolts are arbitrary functions you plug in, including the ones
to push your data further the chain. With spouts and bolts you compose arbitrary DAGs (direct acyclic graph)
to represent your pipeline. Inside the data is transported as key value map (called tuples).
That it’s ! we just explained all the storm concepts. If you get that, you get (part of) the punchplatform idea.
Here is a topology example, one you can setup in seconds using the standalone punchplatform.
It takes data from Kafka, transform it (the punch bolt in there runs log parsers), then
push the results to ElasticSearch.
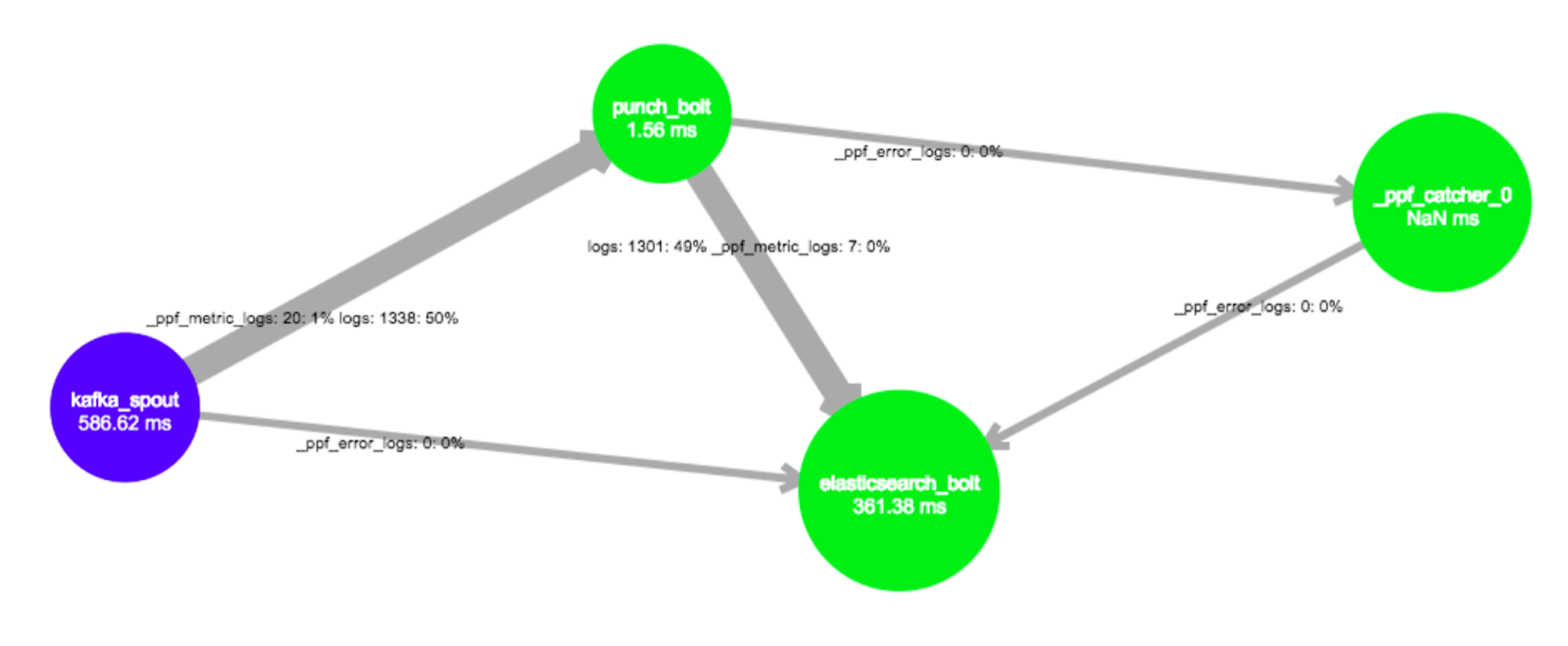
What you see here is the Storm UI topology visualisation. The thicker arrows are the ones where most of the traffic flows.
What about the other arrows ? these _ppf_error and _ppf_metric data streams ? These are used
to deal with real-time monitoring and exception handling. Our users cannot aford to loose
a single log. Should a parser fail, (meaning : you experience thousands of errors/sec),
it is dealt with in a way to make the exceptions transported and saved in Elasticearch too.
These are the kind of features that makes the punchplatform different from a simple Elastic stack.
Coming back to topologies : Storm is great but what is extra great are the concepts.
Punchplatform topologies are represented as plain configuration files. We submit them to
a Storm cluster, but we can also submit them to alternative runtimes. In particular
the punchplatform provides its own runtime, leveraging a lightweight
distributed job scheduler (implemented on top of zookeeper).
That alernative (punch) runtime is well adapted to run small industrial systems such as resilient data collectors.
Less RAM, less CPU, but all the features you expect from a big data platform : monitoring, resiliency, scalability.



0 Comments