The punchplatform is deployed in a number of industrial projects. By now you hopefully know the punchplatform is built extensively on top of Elasticsearch. We run production for several years now, and some of our elasticsearch clusters are fairly big and hold up to a year of data, parsed and normalised thanks to the standard punchplatform parsers. That data is, of course, immensely valuable.
In this blog we briefly explain how we combine Elasticsearch with two companion technologies, Spark and Ceph, so as to provide our users with additional killer features: using Spark they can benefit from extra analytics processing power, including machine learning, and using Ceph they benefit from a scalable and resilient archiving service.
Spark
Say you have a 3 node Elasticsearch cluster, with one index containing 9 documents. Documents are spread among the nodes in shards. This is basically how Elasticsearch distribute the data onto several nodes. To make it simple assume you have three shards. Your cluster looks like this.
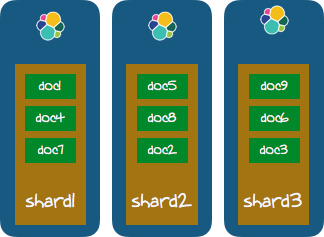
SPARKELASTICONLY Using Kibana or the plain Elasticsearch api you can perform various queries, some of them extremely powerful, making it possible to compute and visualise nested aggregations, top-n and so on.
This is however not good enough. What you want is to run more arbitrary processing over your data and most likely machine learning logic. Here comes Spark. Spark is the de facto standard technology to design scalable machine learning jobs. What you (users) define are so-called pipelines, these basically lets you focus more on solving a machine learning task, instead of wasting time spent on organizing code.
The question is : how do you efficiently execute a Spark pipeline (and in fact, arbitrary spark processing) over your Elasticsearch data ? A naive approach would be to run your pipeline from a remote server or Spark cluster. Should you do that you will transfer all the Elasticsearch data from Elastic to Spark, wasting lots of IOs. This (wrong) approach is illustrated next:
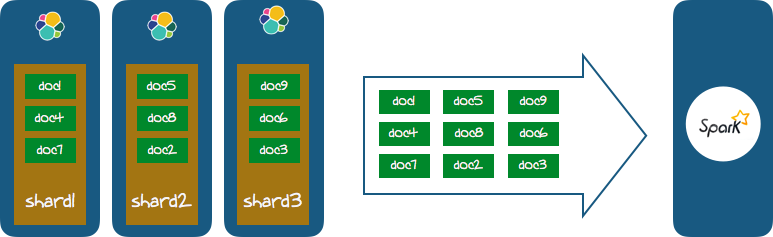
Instead you should transform your Elasticsearch cluster into a hadoop map/reduce distributed engine. There is a connector to do that, it is called Elasticsearch for Hadoop :
Elasticsearch for Apache Hadoop is an open-source, stand-alone, self-contained, small library that allows Hadoop jobs (whether using Map/Reduce or libraries built upon it such as Hive, Pig or Cascading or new upcoming libraries like Apache Spark ) to interact with Elasticsearch. One can think of it as a connector that allows data to flow bi-directionaly so that applications can leverage transparently the Elasticsearch engine capabilities to significantly enrich their capabilities and increase the performance.
Elasticsearch for Apache Hadoop offers first-class support for vanilla Map/Reduce, Cascading, Pig and Hive so that using Elasticsearch is literally like using resources within the Hadoop cluster. As such, Elasticsearch for Apache Hadoop is a passive component, allowing Hadoop jobs to use it as a library and interact with Elasticsearch through Elasticsearch for Apache Hadoop APIs.
This sounds great. And that is what the Punchplatform relies on. Just to make sure we understood it properly we performed various tests to see how the data is transferred back and forth from Elastic to Spark. It works as you expect, like this :
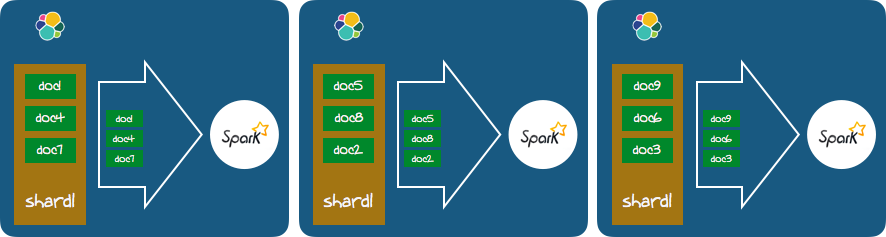
That is, your spark pipeline will be distributed to each node, and each (sub)-pipeline will consume the data from the local Elasticsearch shard. That is : using the locality pattern that makes hadoop works great even on large dataset spread over many servers. We performed various other tests to see what happens when you have more or less shards than spark slaves, what happens when spark must itself save some data to disk (it then use the local filesystem of each node). To sum up : it just works great.
Wait : there is more. Elastic is amazing in filtering out data, and provides means to transform it before returning it to you. If you combine that power with Spark as just explained, you further reduce the amount of data transferred from Elastic to Spark.
What does all this mean ? It means you can perform massive Spark jobs over your Elasticsearch data taking advantage of your Elasticsearch servers (and existing disks), in a way to truly distribute your processing. This is exactly what you need to, say, perform a machine learning job (the fit part) over days or weeks of data stored into your ElasticSearch.
This alone is a killer feature. The punchplatform integrate that setup for you by automatically deploying spark slaves along with the elasticsearch nodes. In a soon to come blog we will explain how the punchplatform machine learning (PML) feature lets you design your Spark pipelines by configuration, not by coding. This is really yet another cool and powerful feature, but not the topic of this blog.
Ceph
Ceph is yet another great technology. We use it to equip our users with an archiving service. They need to store offline data for years, yet be able to efficiently extract ranges of data out of it, for example to perform security investigations on past data. Keeping all that data in Elasticsearch is not the way to go. It would simply requires too much disk. The idea is to keep live data (this said, up to a several months !) in Elasticsearch, and to rely on Ceph for longer term archiving.
Here is what a punchplatform setup looks like. Each server is installed with one Elasticsearch node, and one Ceph node. The local disks from each server is shared among the two.

Ceph basically provides a distributed object filesystem on top of standard local disks. And the killer feature is its erasure coding strategy for replicating data : “Erasure codes allow Ceph to stripe object data over k nodes while adding m additional chunks with encoded redundancy information.”Explained more clearly : instead of replicating the data on two nodes, the data is replicated using a 1.2 level of replication. A sort or distributed RAID strategy. Said even more clearly : you need less disks.
The color on that pictures represent Elasticsearch data (the indexes, in green/blue) versus the Ceph data (in red). Ceph provides us with the storage. We implemented on top of it an archiving service. Our users design data pipelines (the so-called punchplatform channels) that writes the same data to Elasticsearch and to Ceph, yet benefiting from a at-least once/idempotent semantics. Refer to this presentation and to the punchplatform documentation.
Using the archiving service you can efficiently extract data, should you need to provide someone with cold extracts. You can also replay the data. That is, extract the data from Ceph and import it to an Elasticsearch cluster. This is handy for security operators to perform their investigation on past data using Kibana.
Note that such export/import of data can be massive, and take some time to complete. Here come again the punchplatform channels you can design for that purpose. Channels internally rely on Storm or Spark jobs to do the job in a scalable and resilient manner. Should it take a week, it will complete and run safely, fully monitored and supervised, and without compromising your real-time data ingestion.
This basically is what a big data archiving service is about.



0 Comments