In this blog, we tackle the issues to deploy machine learning models from a development (or training) environment to production. Punch keeps on progressing in this area, and provides data scientists and engineers simple but effective tools to facilitate their joint work.
What is the problem ? The gap between development and production stays common, in particular on secured on-premise platforms. Whether in terms of dataset size or access or simply because the working environments are completely different. At the end, when a data engineer receives work from a data scientist, he encounters serious difficulties to industrialise it. In the worst case a complete rewrite of the data scientists work is required.
To address that issue, Punch team has customised a Jupyter notebook called JupyPunch.
Many Punch production features such as source and sink data connectors, package and configuration management, PySpark or Python configurations and dependencies, are directly available in the notebook. The data scientist keeps working in a familiar notebook, without even noticing that behind the scene a (say) PySpark on Kubernetes is at play.
Punch ML Workflow
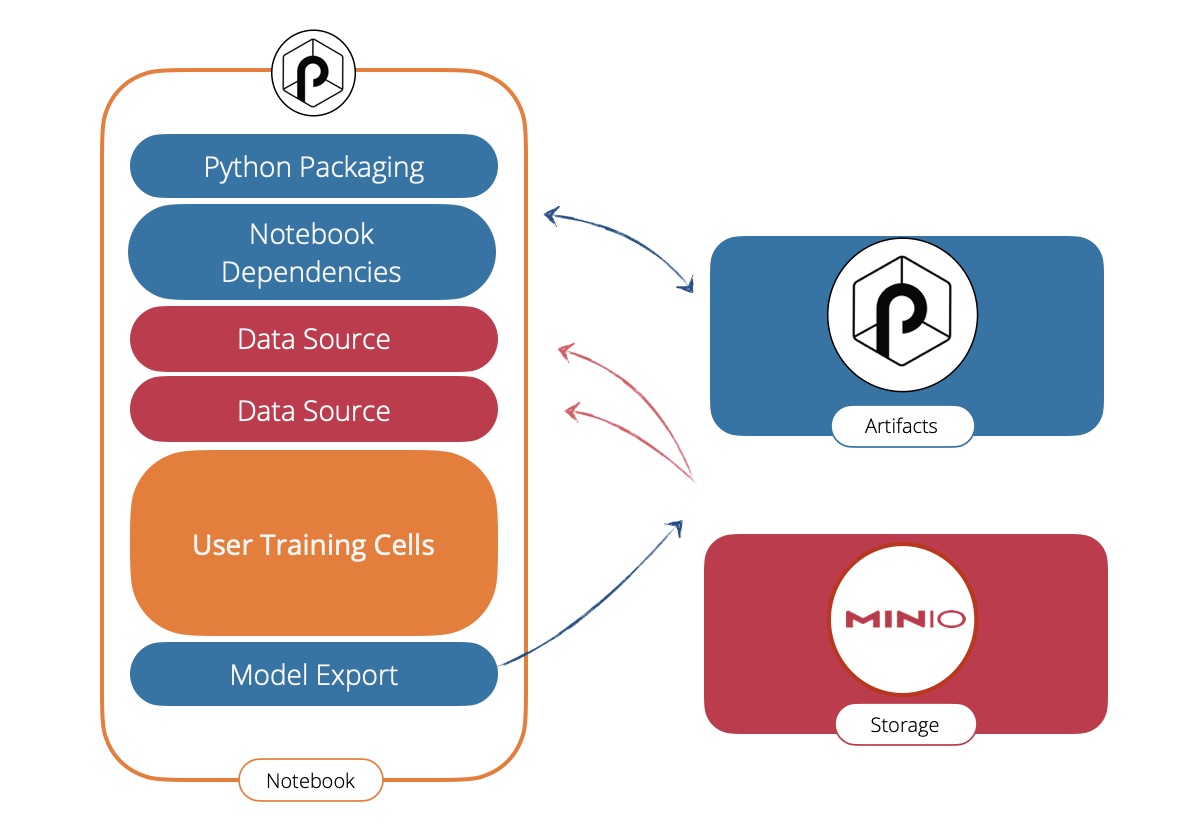
- On the left side, the JupyPunch notebook.
- blue cells are provided by Punch. They provide export/import facilities to deal with the python dependencies, and the generated models.
- red cells are also provided by Punch, they give access to all the supported Punch data connectors. Here for example they provide access to S3.
- in orange the user cells, in our scenario these are the ones that generate the trained model.
- a blue cell (Model Export) takes care of packaging that model to Punch Artifacts Server. Also provided by Punch.
- The righ-side blue component is the Punch Artifacts Server. It indifferently stores models, processing functions, resources files etc..
- Last the Minio third-party (red) component is used here to persist all data.
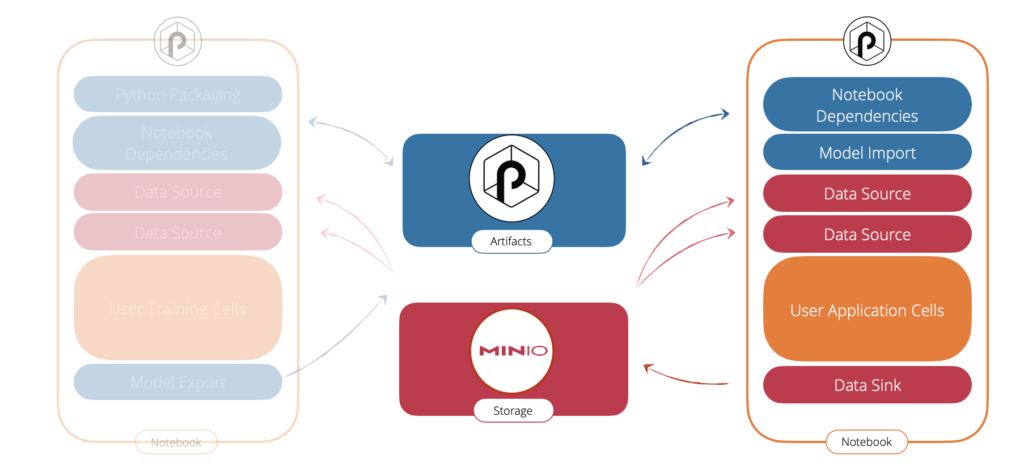
Complete Use case
Let us see this workflow in action. The use case chosen for this demonstration is a credit card fraud detection. Data comes from https://www.kaggle.com/datasets/dhanushnarayananr/credit-card-fraud.
Datasets creation
We first downloaded the kaggle dataset and uploaded it in a working S3 bucket. Our first notebook will then takes care of creating our tutorial datasets to emulate a real-case setup:
- the entire dataset is inserted into an ElasticSearch index. That dataset emulates our production dataset. Only the data engineer can access it.
- a train and test dataset are generated by splitting the input dataset in two parts, both stored in S3. These are the ones used by the data scientist.
Because the training and test datasets are small, this first notebook uses the Punch Python kernel . That kernel is a lightweight single process kernel. You can do the same operation using the PySpark kernel.
Model construction
The second notebook illustrates how a data scientist generates a model, then uploads it to the Punch Artifacts Server. Again Punch Python kernel is used, should the datasets be bigger, the PySpark kernel could be required.
Model usage
The data scientist must now explain to the data engineer how to use his model in order to run it in production. That glue is crucial, it basically tells the data engineer which data/column/type/field from what dataset must be provided to the prediction function.
The way the data scientist does this on Punch is to creates a second notebook that only reads an input dataset, applies the model, then save the result somewhere (or simply print it). Once done, that entire notebook is versioned and exported in Punch Artifacts Server.
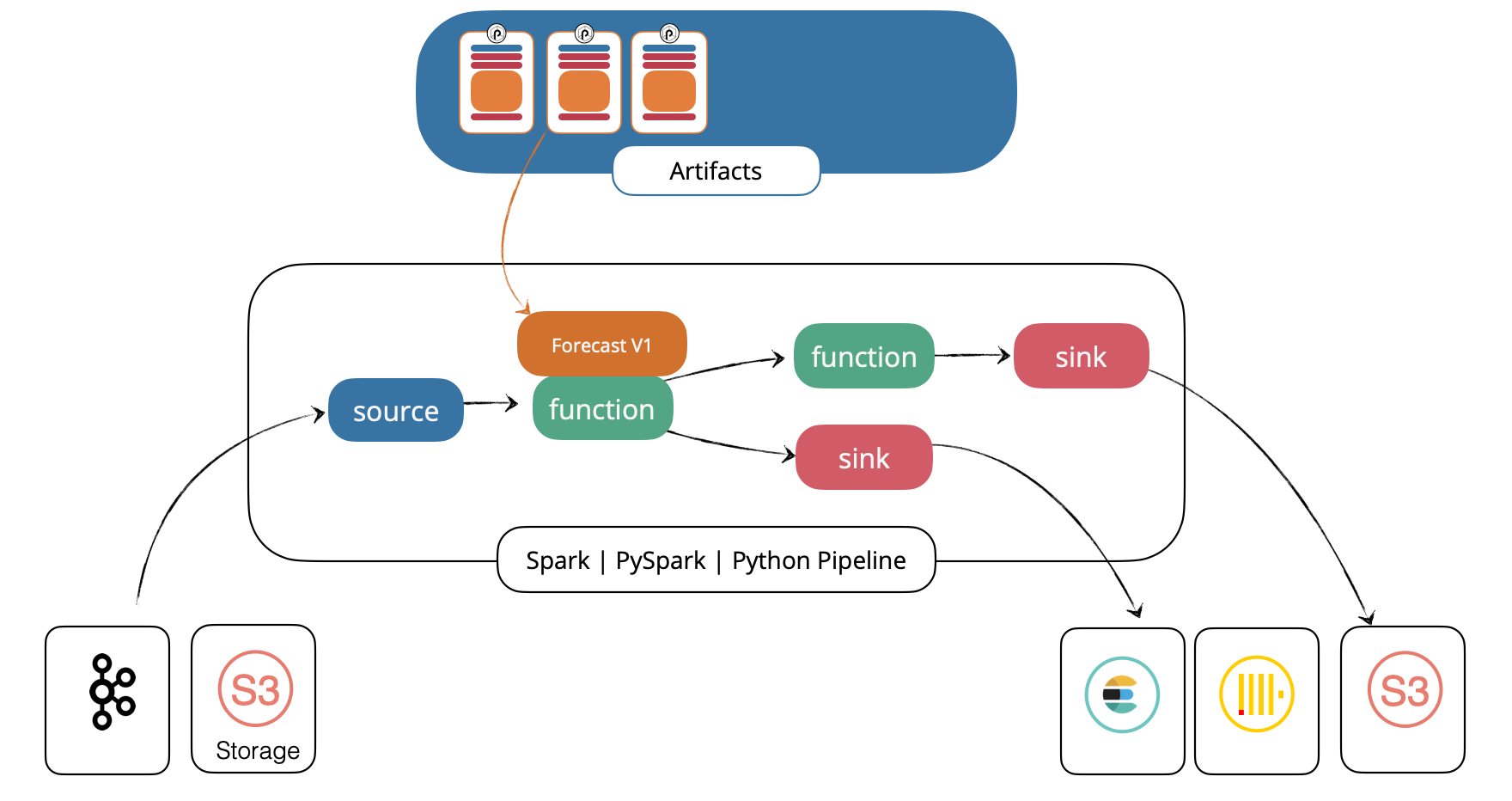
Notebook to punchline
The notebook is now automatically transformed into a Punch pipeline (called punchline). The data scientist clicks on the Punch packaging button in the Jupyter toolbar and fill in the form.

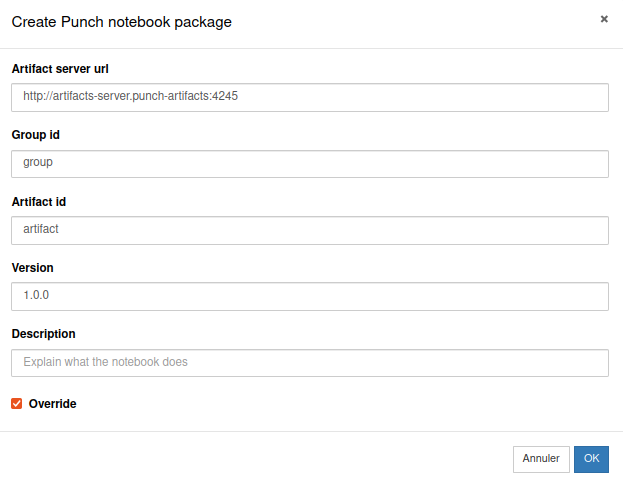
A new folder (named package_<group>_<artifact>_<version>) is created in the data scientist working environment. There, a sample punchline is available that shows how to invoke the notebook as part of a production ready pipeline.
This punchline can then be sent to the data engineer with the dependencies listed in. Data engineer only has to replace sources and sinks with production ones. And voilà, the model is ready to production!
---
apiVersion: punchline.punchplatform.io/v2
kind: SparkPunchline
metadata:
name: punchline-notebook
spec:
containers:
serviceAccount: admin-user
applicationContainer:
image: ghcr.io/punchplatform/punchline-pyspark:8.0-dev
imagePullPolicy: IfNotPresent
resourcesInitContainer:
image: ghcr.io/punchplatform/resourcectl:8.0-dev
resourcesProviderUrl: http://artifacts-server.punch-artifacts:4245
dependencies:
- additional-pex:demo:dependencies:1.0.0
- model:demo:credit_card:1.0.0
- file:demo:credit_card_notebook:1.0.0
engineSettings:
spark.hadoop.fs.s3a.access.key: "minio"
spark.hadoop.fs.s3a.aws.credentials.provider: "org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider"
spark.hadoop.fs.s3a.endpoint: "http://minio.object-store:9002"
spark.hadoop.fs.s3a.path.style.access: "True"
spark.hadoop.fs.s3a.secret.key: "password"
spark.executor.instances: "3"
dag:
- id: source_1
kind: source
type: elasticsearch
settings:
http_hosts:
- host: punchplatform-es-default.doc-store
port: 9200
scheme: http
index: credit_card
security:
credentials:
password: elastic
username: elastic
out:
- id: notebook
table: table
- id: notebook
kind: function
type: notebook
settings:
notebook: demo:credit_card_notebook:1.0.0
inputs:
- from: source_1_table
to: data
outputs:
- from: everything
to: table_1
parameters:
nb_rows: 5000
out:
- id: sink_1
table: table_1
- id: sink_1
kind: sink
type: elasticsearch
settings:
http_hosts:
- host: punchplatform-es-default.doc-store
port: 9200
scheme: http
index:
type: constant
value: credit_card_results
security:
credentials:
password: elastic
username: elastic
All notebooks are available here.
Conclusions
To recap, Punch provides simple and well known tools to facilitate data scientist and engineer collaboration. Notice that Punch components do not vendor lock your data applications in any way, you keep using best-of-breed open source technologies. Punch added value is simply to provide you with lightweight but robust workflows to pass to production, and once there to easily maintain or update it.
Thanks for reading our blog !


1 Comment
Punch the 8th - The Punch · February 3, 2023 at 09:55
[…] this topic is of interests to you, check out our dedicated blog post. There are more features in particular to facilitate the deployment of (orange) cells to production […]