The punch 8th has been released for a few months, and we are now up to deliver the 8.1 version. Here are some news.
Punch is a log management and data analytics solution designed using a Function-As-A-Service/Serverless architecture. It is lightweight, modular, and now completely cloud native. In this blog we focus on the latest features, do not hesitate having a look at the online docs.
Serverless
Punch is designed to run arbitrary processing functions, and in particular log parsers. Our business goal is to bootstrap customer projects with ready to use parsers, pipeline and functions so that they quickly start with a complete collect-transport-parse-archive-index-extract solution. To achieve that, Punch is built on a simple and powerful serverless pattern. Here is how it works:
Say you have a function. First, you package and ship it to the Punch Artifacts Server. Below, a snapshot of the Punch UI with the Artifacts Server tab in foreground. You see there all your functions, packaged and identified using a simple yet robust versioning scheme.
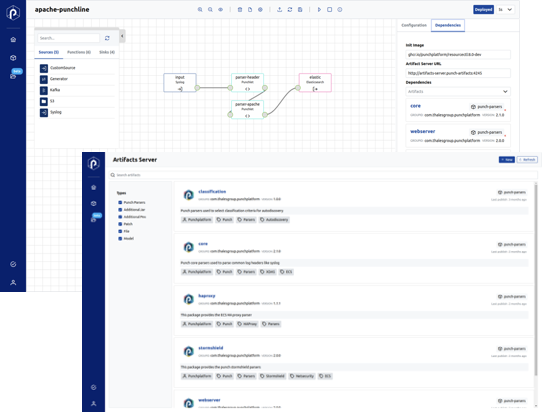
Once your function is there, you then deploy it as part of stream or batch pipelines. The top left side of the UI shows the Punchline editor.
That is the Punch. As simple as that. Simple but powerful because the pipelines are transformed and run as lightweight single process python or java containerized apps, or if you need power and scale, as Spark or PySpark applications submitted on the fly onto your Kubernetes platform. Many use cases can be covered, from log management or IoT to larger scale analytics use cases, with a handful of software components.
Log Management
Punch provides a unique log parser development SDK; and all the necessary configuration and deployment tools to simplify the deployment and management of your parsers, schemas, lineage, enrichment files etc..
The Punch specialized programming language makes log parser development simple, robust (the SDK includes unit tests facilities), and elegant in that log parsers are functions like any others. The day you deploy a ML model or a custom python function along with your parsers, that will appear as simple to you.
Here is a summary of what the Punch lets you solve:
I want to deploy the latest cisco parser v2.0.0 that phil just improved to take care of new equipments log formats.
Or
I would like my log parsing pipelines to automatically take into account the latest enrichment files from my Threat Intelligence Platform.
Punch 8.1 introduces interesting new log management features; here they are.
Implicit versus Explicit Error Handling
Punch programming language has been improved to allow parser developers to easily react to incomplete or incorrect logs. Errors are automatically generated and handled with. The generated errors are ECS-compliant and designed to facilitate their vizualisation using Kibana and their post processing.
Where the Punch shines is in its capability to handle partial errors: if a log was successfully parsed except for some detailed field. For these cases, triggering a complete parsing failure is overkill and actually complicates end-user operations and analysis. Instead, a partially parsed document is generated with extra information to let the user know about missing or incorrect fields. In some way it is not an error anymore.
That strategy drastically simplifies users life in detecting and tuning these secondary errors, without falling back to traditional error queues with tons of unparsed logs.
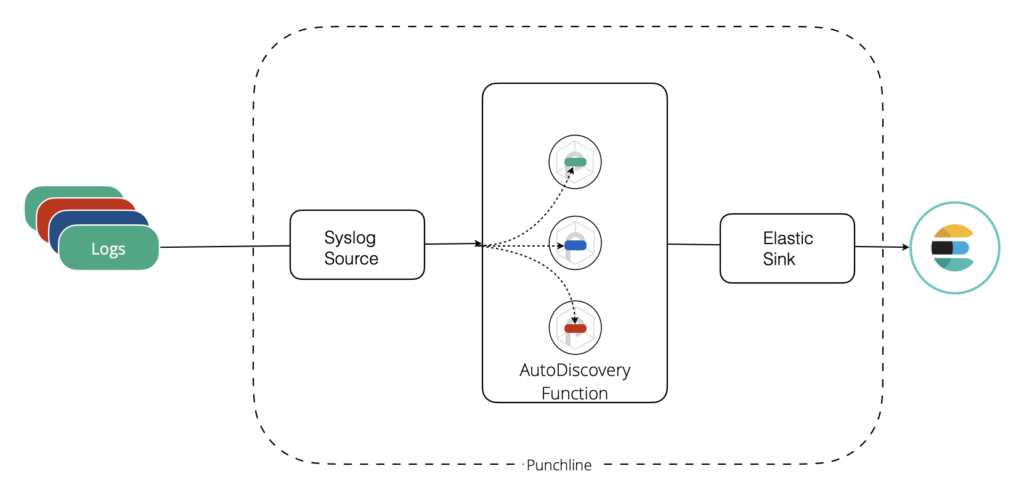
Log AutoDiscovery
This feature is extra simple to explain: you can send all your logs to a single Punch entry point, Punch will take care of choosing the right parser for each incoming log. This feature is tricky to implement. Refer to the online documentation for details. Note that Punch provides unsupervised learning strategies to help optimise the discovery phase. We are so happy with that feature that we now recommend to deploy log parsing pipelines using that strategy activated by default.
Sigma Rule Support
Up to now the Punch only provided an Elastalert module, used in turn by Punch customers to execute Sigma detection rules. Sigma rules were not a Punch feature on its own.
The interesting fact is that a vast majority of these rules are quite simple to implement, it basically suffices to check that some of the log field(s) match or contain some value(s). Said differently, a simple stream processing function can do the job quite efficiently, no need to deploy a batch strategy to periodically check if rules are matched using Elasticsearch (or other backed technology) queries.
What is now available in Punch is a Sigma rules compiler that directly generate punchlang rules, which in turn are automatically deployed in streaming pipelines. If rule(s) matches, an enriched document is generated on the fly.
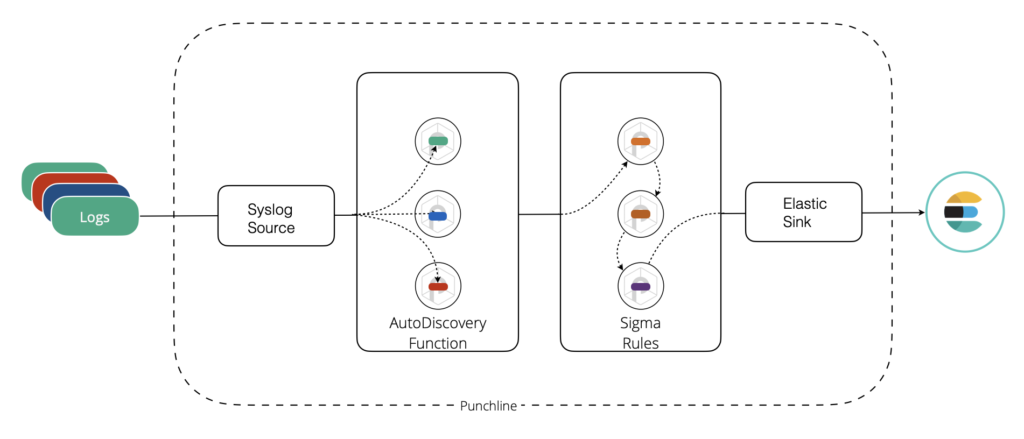
That feature is interesting for two reasons. First, Punch can evaluate a Sigma rule without any Elasticsearch or other database support. Your platform blueprint is drastically reduced. In some cases, you can implement most of your detection rules in a tiny Punch possibly deployed on edge collectors.
Second, Sigma rules generation and deployment benefit from all the Punch configuration management features, just like other processing functions and parsers: rules are versioned. You have a simple but effective UI, and REST APIs if you would rather like to orchestrate Punch applications from your configuration plane or UI.
Data Engineering and Data Science
Let us move away from log management. Punch 8.1 brings in a major new feature called JupyPunch. JupyPunch is a Jupyter notebook preloaded with Punch connector libraries, and added with many Jupyter magic functions to ease data science working experience on development or production platforms.
An example will better illustrate what you can do with it. Say you have data stored in a S3 store, in the cloud or on-premise (probably by leveraging a Minio object store). You start by working in a notebook to (say) train a new model on that data. Here is a simple setup that makes you work in a production-like environment yet lightweight and easy to setup:
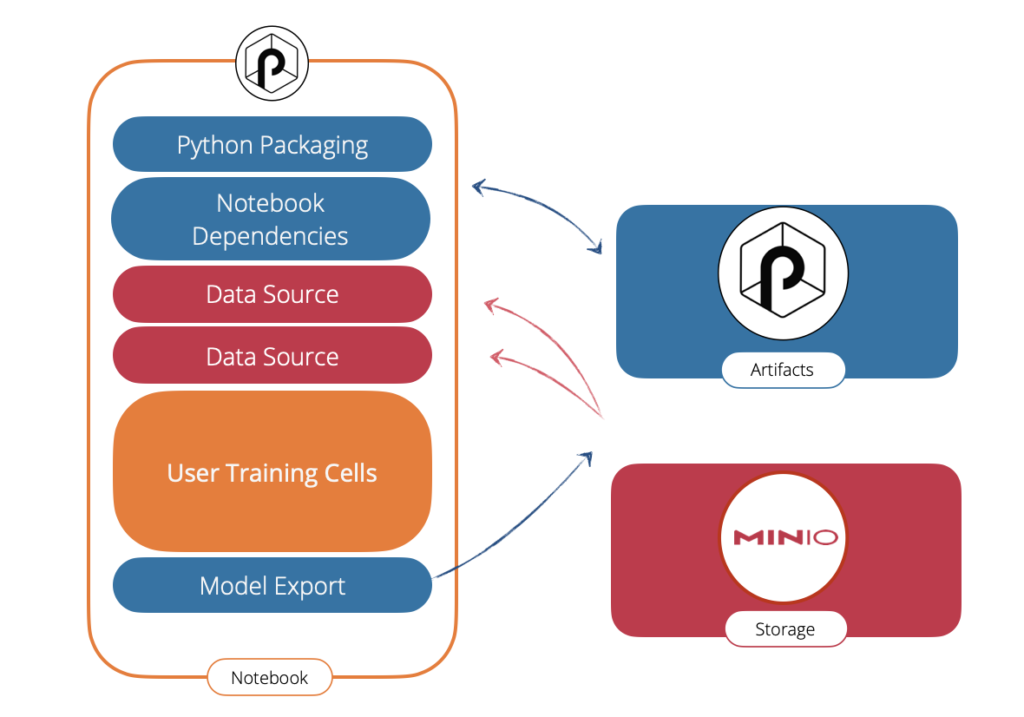
- On the left side, the JupyPunch notebook. In there you have:
- blue cells are the one that let you safely store and load your notebook dependencies. For example you might need to import third-party scikit-learn libraries.
- red cells let you load your data from all the supported Punch sources connectors. In this case S3, but possibly Elasticsearch, Clickhouse, Kafka etc..
- In orange your cells, only you know what is in there. Assuming you train a model, when happy you will want to save a versioned release of it and use it for prediction. For that you will use ..
- a blue cell (Model Export) that takes care of packaging your model to some model registry.
- The right side blue component is the Punch Artifacts Server. It indifferently stores models, processing functions, resources files etc..
- Last the Minio third-party (red) component is used here to persist all our data. The Punch Artifacts Server also uses it to store its data and metadata.
The beauty and simplicity of this setup is that with only three components deployed on your laptop or Kubernetes, you have it all. Behind the scene when you run your notebook, what is executed is a powerful Punch PySpark, Spark or Lightweight Python applications. This is all transparent to you. In particular you do not have the burden to setup a Spark on Kubernetes environment.
Say now you want to apply your model onto some dataset. Here is what you would do:
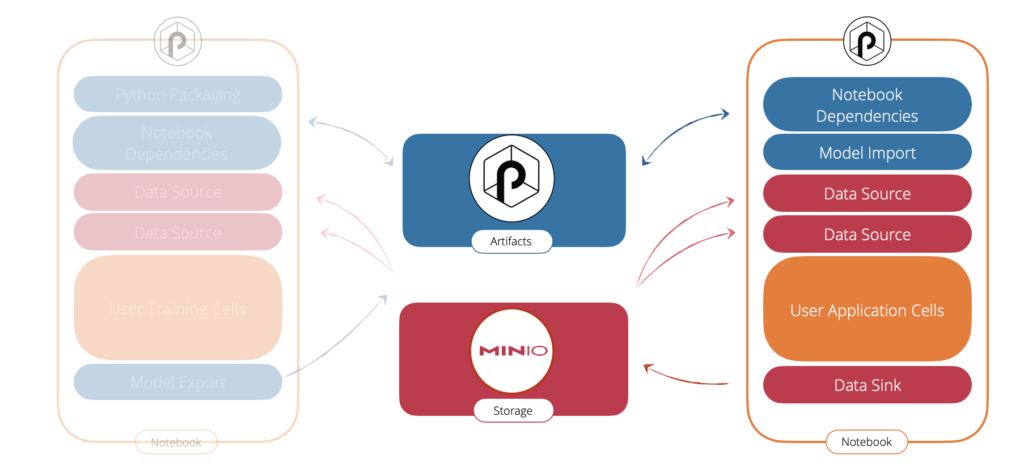
A second notebook will do the job. It loads the model generated by the first one, then your (orange) user cells will perform the predictions, and last (typically) it saves the prediction data using a (red) sink back to S3.
If this topic is of interests to you, check out our dedicated blog post. There are more features in particular to facilitate the deployment of (orange) cells to production pipelines.
Cloud Native
After reading the previous paragraph you might wonder why Punch provides such software components ? After all, a mlflow, a dataiku, and/or various data cloud services excel in solving these kinds of MLOps issues. That is true but for two first points. First, all these components best work on a fully managed service stack. If you need to deploy them on Kubernetes and worst; on-premise, well: good luck. Second, Punch keeps focusing on deploying the minimal set of components needed. No extra databases here, just what is needed; yet providing high level UIs and REST APIs. In many industrial data analytics solutions, you do not need the many extra (and by the way great) features offered by full-fledged data management solutions. The simplest, the easier to set up, to audit and maintain.
Let us briefly explain what a Punch architecture looks like. Punch components best run on top of Kubernetes. Either yours if you run on premise, or the one from your cloud provider. Punch has no adherence with any Kubernetes distribution. In fact, having Kubernetes is now a commodity.
Much less easy is to have all the required data, monitoring and security services deployed on it. Punch itself does not address this issue. It is up to you to choose a best solution. Our preferred solution is Kast, a Thales group distribution that provides all the required services with lots of interesting security, monitoring and data services. Here is what it looks like:
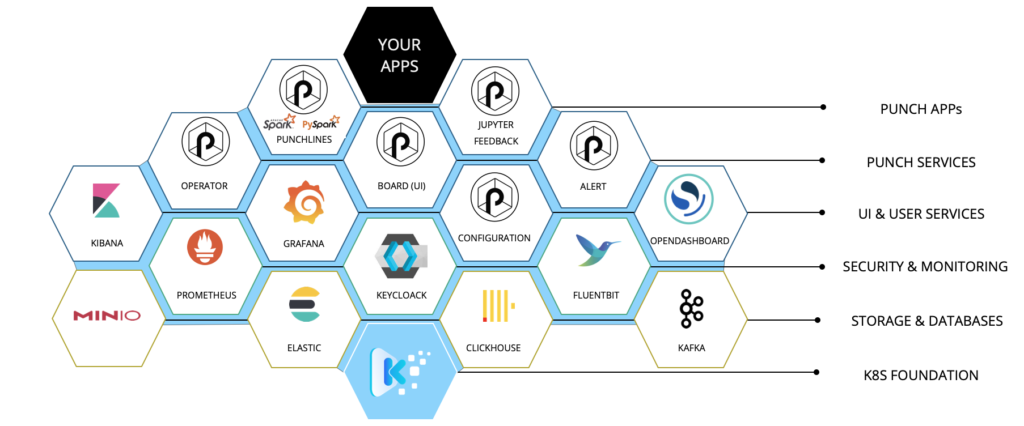
Kast provides all the Kubernetes, Security, Monitoring and Data Services. On top of it Punch consists in a small number of dockerized components that provide higher-level configuration, packaging and deployments capabilities, plus a (large) number of cybersecurity and function-as-a-service features.
For the amateurs, Punch provides:
- Kubernetes operators : to execute the various data pipelines (spark, java, python soon rust).
- JupyPunch notebook presented before.
- a UI called Punch Board.
- Artifacts and Configuration Servers
- SDKs and tools to work with parsers, sigma rules or arbitrary java or python functions.
Once these services are installed, you simply upload your functions, deployed in turn in pipelines. These actions are performed using UI or high level API calls, not using low level kubectl or helm commands.
Conclusion
We hope this blog helps to highlight Punch features. In all cases, do not hesitate contacting us. The Punch is very easy and publicly available to work with. We also provide free releases for students or academics in order to focus on fun or challenging data science use cases.
Once more, I personally thanks the Punch team for its commitment and constant hard work.



0 Comments