You have interesting data: radar data, security logs, Iot data, pictures, and you wonder how to best combine archiving and indexing capabilities. To perform efficient queries and benefit from optimal (near) real-time performance, you need to select the right (indexed) database. In contrast; to archive lots of data for months or years you are likely to need a cheaper solution. Indexes takes room and it can take up to 20 times more storage capacities to store indexed data compared to storing only the raw compressed data.
Today there are many storage solutions (on cloud or on prems), popular columnar file formats such as parquet, orc (or even arrow which is more specifically suited for in memory data), and many powerful AI/big data tools and APIs available. Using these it is easier to think of your archive data not as frozen data you extract once in a while, but as data you will consume often from various applications : to compute statistics, for cybersecurity retro-hunting, to calculate machine learning model calculation, etc..
The good news is that you do not need a giant hadoop system to benefit from that. A basic S3, combined with one of the many great solutions like dataiku or databrick gives you plenty of possibilities. The punch is in the same area. Because it started as a log management solution, and was equipped with machine learning capabilities shortly after, the archiving versus indexing question is a key one.
This blog provides you with a quick recap of punch capabilities and introduces a new punch concept : punchlines.
Archiving
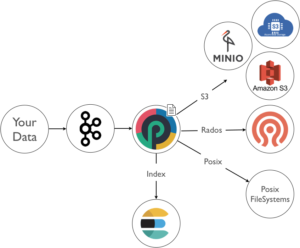
Let us start with archiving. S3 is a popular and cost effective solution. You can archive into S3 using a simple punch application that you define using a json configuration file. It is a called a punchline. Here is an example leveraging the minio S3 storage solution.

The punchline defines your pipeline. In this example it is simply : read my data, then archive it into S3. It could be a Ceph storage as well, or plain files or .. well it does not matter so much. What is more important is that you do that using a simple configuration file (no coding), and that you benefit from idempotency, exactly or at-least once semantics, compression, security digests for integrity controls. Punchlines lets you access ready to use modules to deal with these requirements.
If you are serious about not loosing data, it is likely that you add a Kafka hop as illustrated next. It is as easy. The Kafka server(s) will act as intermediary buffer with a few days of data so that you can cope with failure or application restart without data loss.

Doing this alone may not be good enough at large scale. You will end up with millions of objects or files. The punch provides you with additional capabilities to index archive metadatas in a separate (elasticsearch) database. In turn it makes it possible to locate and extract the archived data more efficiently. Here is a sketch of the possibilities:
In short, the punch provides you with ready-to-use archiving features. If you want more details, please refer to our archive module documentation).
Indexing
Elasticsearch has been punch primary choice from day one, and the punch is still an elasticsearch-centric solution. Each new elasticsearch release brings in great improvements, and together with Kibana provides our users with an extraordinary data analytics solution. Besides, it is really excellent for many use case (log management, monitoring, textual data), but it is also quite good for other use cases. Having one technology to deal with all sort of data is a key advantage.
To do that you use again a punchline. It could be : read my data, parse it, enrich it, then index it into Elasticsearch.

This said, some other technologies are very attractive. One in particular is clickhouse, a SQL columnar distributed database that is extremely efficient for some important use cases such as time series and geospatial data. The punch can ingest data into Clickhouse at high rate.

The punch can also ingest data into MapD, or any standard sql database.
Doing Both
At the end, you often need to both archive and index your data. The punch let you do that the way you want. For example :
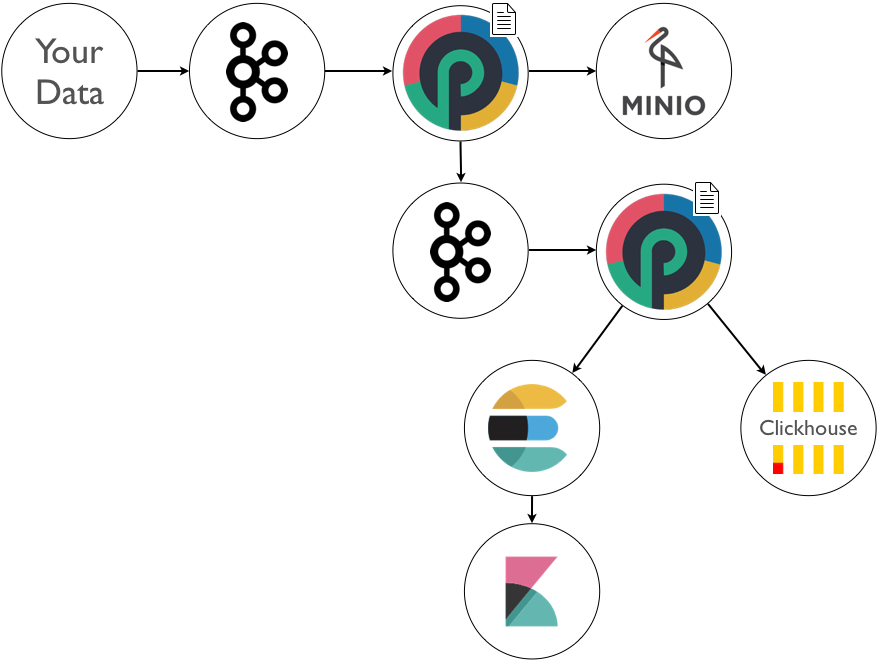
The thing is, doing this increases complexity hence operational costs : failures, data loss, upgrade, overload control, security, multi-tenancy etc.. The punch provides you with lots of industrial features to deal with these issues but this is not the topic of this blog. As long as you have a good solution you are good to go.
Process Your Data
Your data is there, ready to be used, in S3, Kafka, Elasticsearch, Clickhouse. Now come into play yet other punchlines : the ones to crunch your cold or hot data.
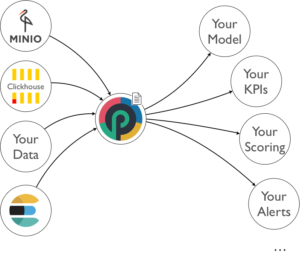
With punchlines, you can implement virtually all types of use cases : stream, batch, sql, machine learning. Let us focus on how exactly you do that.
A punchlines is a (JSON) configuration files that represents a graph (DAG) of processing functions. Punchlines are first transformed by the punch runtime into a spark|pyspark|python|storm|java application, then submitted for execution to the right target runtime engine. Punch supports several runtime executions but this is (again) out of the scope of this blog.
To illustrate this here is a small extra simple demo. We have a punchline that simply generates some (dataframe) data and print it out. This punchline is so simple that you can actually choose to execute it as a java spark or as a python pyspark app. Here is how you execute it as a spark application (the default mode):
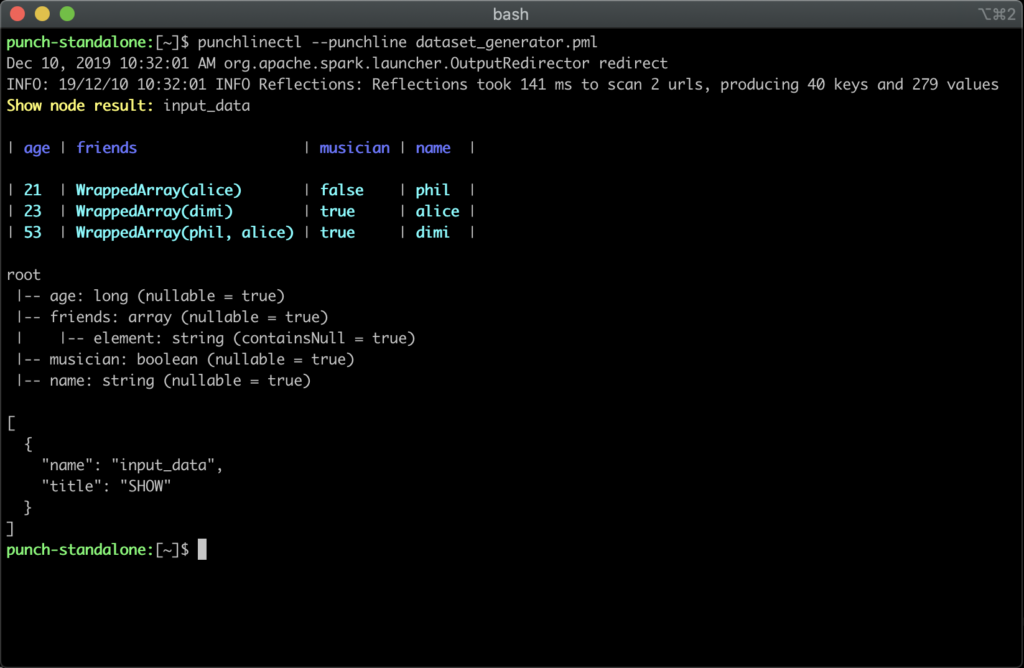
Now execute it but as a pyspark application :
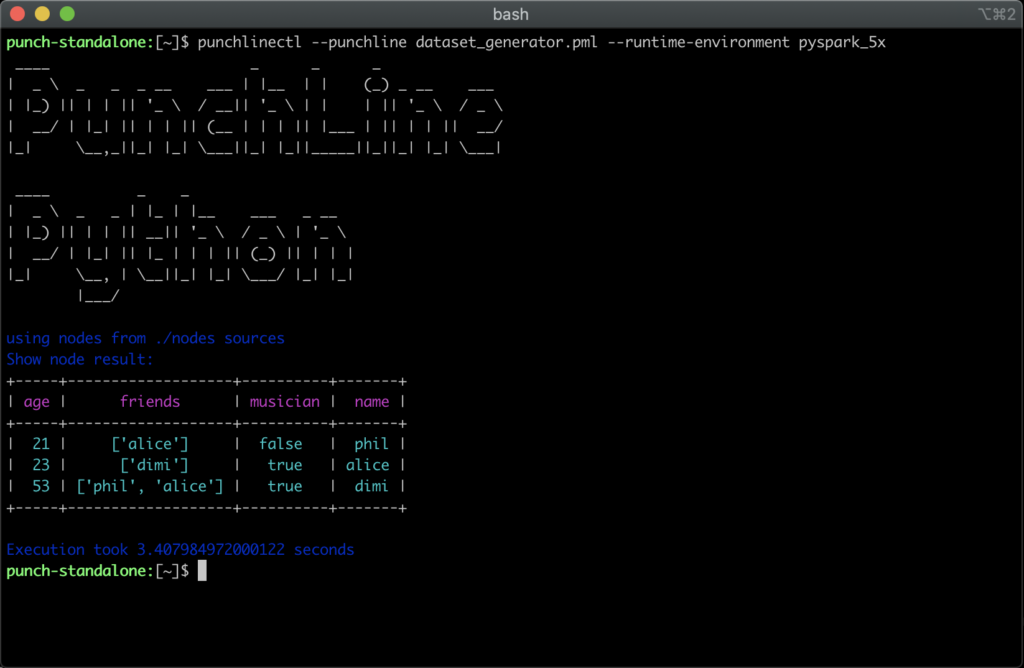
The output is not exactly the same, but the results are equivalent. The punch provides you with many nodes, but you can write your own. The punch is lightweight and many punchlines are just transformed into single-process apps, deployed on one server. If you need to scale punchlines are turned into full-fledged spark apps and submitted to a real spark cluster. Punchlines already equip some customer solutions in particular to perform machine learning or aggregations tasks.
Special Note for Our Existing Customers
Here is a small history recap :
- 2015 the punch provided you with so called topologies. These were in fact apache storm applications.
- 2017 then we introduced light topologies. These are still Storm compatible apps but run in a lightweight single-process engine and are well suited for small footprints configurations.
- 2017 Then we introduced pml, these are Spark apps. With pml you benefit from lots of additional connectors or functions, in particular the full set of mllib algorithms.
- 2019 Then we supported SparkStructuredStreaming pml variants. Same idea but you can go stream, not just batch.
- 2019 Then we made it possible for a pml to run pyspark.
- 2019 Then lately plain python, i.e. not even pyspark to bring in third party python libraries such a Keras or TensorFlow.
STOP !
You are certainly completely lost. The reason we decided to stop with all these names is simply that all these animals are in fact just the same concept. An application is just a graph of node. It can be storm, spark, python, logstah. At the end it all comes down to a DAG. DAGs are great. If you go and think DAG, you will benefit from lots of ready-to-use graph nodes, and an easy way to add you own. The punch represents all these variants using the same json|hjson representation … and these are now simply called punchlines.
See a punchline as an elementary application unit. A punchline can be :
- a (stream) firewall log parser.
- a (stream) cybersecurity application that will enrich your logs with thread-intel data on the fly.
- an (stream) S3 archiving processor.
- a (batch) aggregation application to compute some indicators.
- a (batch) machine learning application that computes a model out of a dataset.
- a (stream) machine learning application that will score your ingested data in real time.
- etc..
If you go production, you will need a few extra features to assemble your punchlines into consistent and manageable applications :
- the ability to schedule punchline periodically in a way (of course) resilient and distributed
- the ability to group several punchlines into a logical higher level app. This is called a channel.
- the ability to group your punchlines and channel as part of a tenant.
- the ability to express more complex runtime orderings between your channels and punchlines
The Punch provides all that. The most distinguish characteristics of the punch is to provide you with a complete solution that you can deploy on your on-premise infrastructure. No need to have a Cloud, a Kubernetes or something like that. If you have only one or a few servers running Centos, Debian or Ubuntu, your are ready to go. This said if you do have a Cloud, a Kubernetes, a Spark cluster, a Nifi runtime, punchlines or punch modules can be deployed as well.
All that are good news except for one difficulty: it is not easy to explain what you can do with the punch. Because you can do a lot of things.
Of course, punchline will make their way in punch releases with complete backward compatibility. They start appearing in the Craig 5.x release.
The Punch Team