The Craig punchplatform version 5.1.2 is released. This post gives an overview of the new features.
New Features
The Craig punchplatform 5.1.2 has a number of important new features. First off, it leverages many important component updates:
It also brings in a number of new features. Here is a quick overview.
Azure Blob Storage Connector
Punch pipelines are running in various runtime environments, and in particular, consumes data from the Azure blob storage. A new punch spout has been specifically designed so as to consume data (i.e. files) fro azure blob storage in a way to continuously consume new data. Similar to consuming Kafka topics, this entails a subtle strategy to deal with checkpoints, as well as the ability to consume only updated parts of existing files.
The azure spout if completely generic and can consume arbitrary textual data. But there is more:
NSG Connector
The Punch is a great backbone to implement cybersecurity pipelines and can be (and in fact is) used to deploy end-to-end detection scenario. This requires a complete end-to-end path from data collection, filtering, parsing, enrichment, alert detection, and of course indexation into Elasticsearch. Forsecuring azure based solution, we also provided a specialized connector to consume network security group related data (NSG).

NSGs are at the heart of virtual network isolation, and watching their related logs is key to have a clear view of your security architecture and to implement the required alerts.
Leveraging Siddhi 4.x
We updated our siddhi rule engine. This had a number of benefits, some of them required to implement various precise rules such as detecting silent equipment, joining several streams and relying on partitions.
Partitions divide streams and queries into isolated groups in order to process them in parallel and in isolation. A partition can contain one or more queries and there can be multiple instances where the same queries and streams are replicated for each partition. Each partition is tagged with a partition key. Those partitions only process the events that match the corresponding partition key.
Partitions allow you to process the events groups in isolation so that event processing can be performed using the same set of queries for each group.
The Punch provides a very elegant and original solution to embed siddhi rules in functional pipelines. Rules are integrated as part of the punch language itself. This integration makes it easy to prepare the data before its ingestion into the rules and makes it as easy to post-process the data generated by the rules. Cleaning and normalizing data is the essential focus of the punch, so as to ensure easy data searching, visualization, and manipulation. Data generated by alerting rules are just like any other data.
The latest Craig5.1.2 standalone ships in with several siddhi examples.
Punch Kibana Plugin
The punch plugin keeps improving. It lets you navigate through your platform configuration, design Spark and machine learning jobs, help you extracting data to files or other destinations, and more. The best way to discover it is to download and check out the latest standalone.
Punchplatform Spark and Machine Learning Sdk
Big news here ! Our PML feature has been confronted with real users and use cases and has benefited from significant improvements.
User Experience
Starting with the user experience, the punch Kibana plugin PML editor is now leaving its beta status. Much more elegant, better documented, it makes it significantly easier and natural to design Spark pipelines (with or without machine learning).
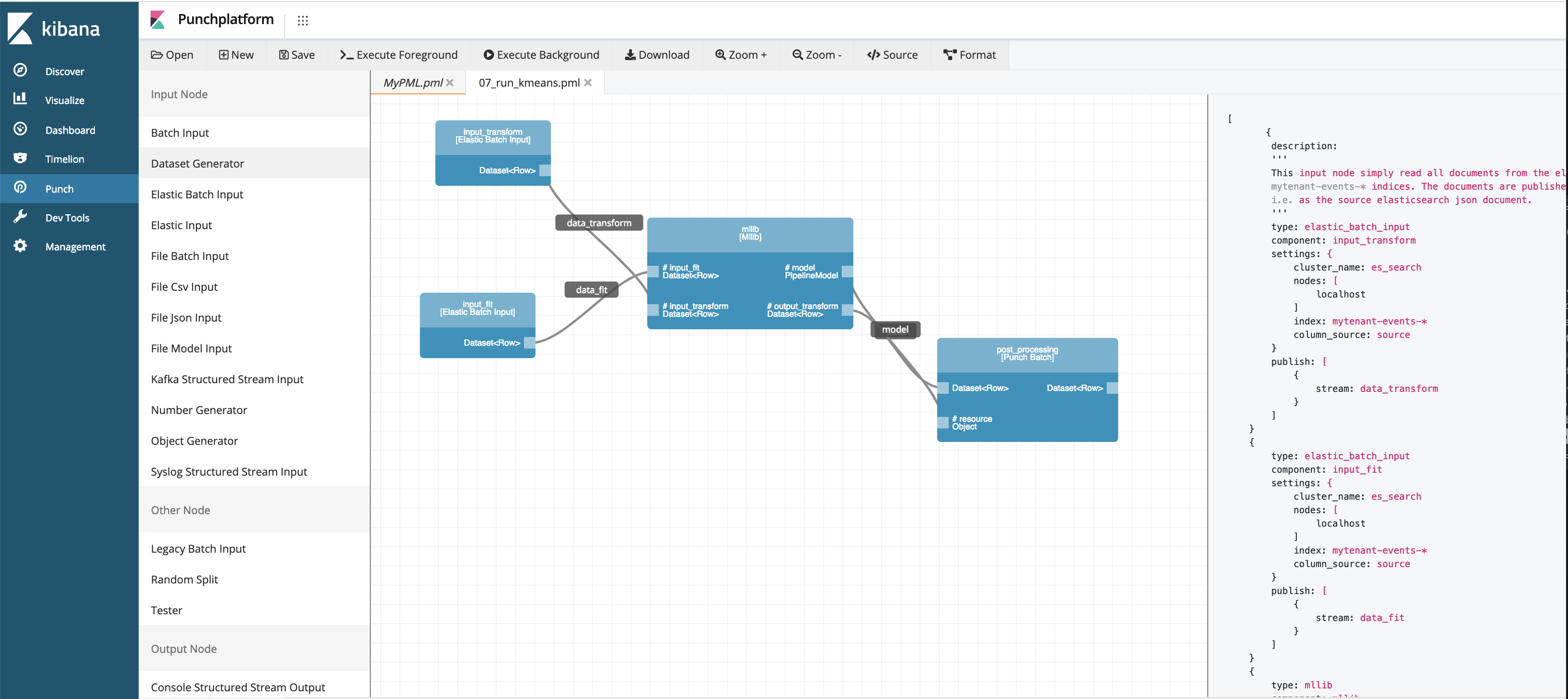
The generated PML files benefit from a clean and powerful HJSON syntax. Self-documented, straightforward to understand, they allow our data scientist users to deliver to production platforms notebook-like descriptions of their spark processings. This in turns frees them (and in fact not only them but everyone) to struggle with coding, low-level APIs adherence, and complex dependencies.
We also added new PML nodes and improved many of them to make it easier to work with files, to consume data from elasticsearch or from kafka. PML jobs can now leverage Spark Structured Streaming. This means you can design powerful stream processor application leveraging Spark QL queries in just a few clicks.
Having a robust PML feature is key to the Punch and one of its most important differentiator. In particular, it is used internally by the Punch extraction service to let users define then run extraction jobs over large datasets.
Dealing with ML models
We also significantly improved PML with respect to manipulating machine learning models. First, we added and improved our nodes to save and load models using files. It is now much more simple and natural to design several pipelines to compute and generate models from one hand, and deploy them into detection pipelines to the other.
Plug In Your Own Spark Nodes and Stages
From day one, we designed PML so as users and customers can deliver their own Spark and Spark MLlib nodes and stages, with no adherence to any other API, and let them enrich their punch platform with these.
In this release, the punch automatically discovers your nodes and stages and make them available in the PML editor. This feature is a key as it allow our users to provide their own add-on to a punch market place.
Leveraging Spark 2.4
Let us insist: the Punch and PML in particular aim at leveraging open technologies. Spark is constantly improving and evolving. Some of the recent improvements are listed hereafter. Just know you benefit from all of these.
- Built-in support for reading images into a
DataFramewas added (SPARK-21866). OneHotEncoderEstimatorwas added, and should be used instead of the existingOneHotEncodertransformer. The new estimator supports transforming multiple columns.- Multiple column support was also added to
QuantileDiscretizerandBucketizer(SPARK-22397 and SPARK-20542) - A new
FeatureHashertransformer was added (SPARK-13969). - Added support for evaluating multiple models in parallel when performing cross-validation using
TrainValidationSplitorCrossValidator(SPARK-19357). - Improved support for custom pipeline components in Python (see SPARK-21633 and SPARK-21542).
DataFramefunctions for descriptive summary statistics over vector columns (SPARK-19634).- Robust linear regression with Huber loss (SPARK-3181).
In particular, cross-validation support is a significant improvement that makes Spark (and PML) easier to use by the data scientist community, today still more at ease with python based notebooks. Helping data scientist moving toward production-ready technologies is punch mission.
New Friends and Improvements
Last, we keep integrating important components and introducing new features to keep building a lightweight yet complete solution:
- KeyCloak is integrated to secure multi-tenant data access.
- Logstash can be deployed as part of channels to (typically) act on the edges, pulling or pushing data from/to external sources
- Our elasticsearch output connector now supports SSL
- Punch channels can run topologies using our lightweight single-process Storm engine, better suited for small platforms.
- Spark PML jobs can similarly be executed in a single process application
Many thanks to you for going through this announce.
Do not hesitate to get in touch with us contact@punchlatform.com.



