Overview
Apache Nifi is a popular technology to handle dataflow between systems. Using a simple interface to create diagrams, you can manage where the data goes and how is it processed. Just like many similar frameworks, Nifi provides a bunch of built-in nodes to deal with various data sources or sinks. Using Nifi processor API, you can easily create your own.
This said, parsing logs is not that easy, and simple things such as key-value, grok, filtering or even content-based routing lead to a lot of struggle and you end up with fairly complex flows. In this area, the Punch (and other technologies such as Splunk, Logstash, QRadar etc..) excel. The Punch provides a dedicated language (the punch language), and the concept of punchlets that are small parsing functions you deploy in your stream processing engines. The punch leverages several stream processing engines including its own lightweight variant. At the end what is important is to leverage punch parsers.

These parsers have a great value, there are tenths of them, used by various customers to deal with all sorts of data. Punch primitives make it easy to enrich the data on the fly, to check it conforms to some schema, to detect interesting patterns and more.
Long story made short: some customers use Nifi and wanted to benefit from punchlets. No need to migrate from Nifi to another streaming engine, punchlets are now fully supported as part of Nifi. This blog explains it all.
The Punch Processor
Processing data using punchlets in Nifi is as simple as inserting a PunchProcessor in your dataflow. Here is a simple flow example:
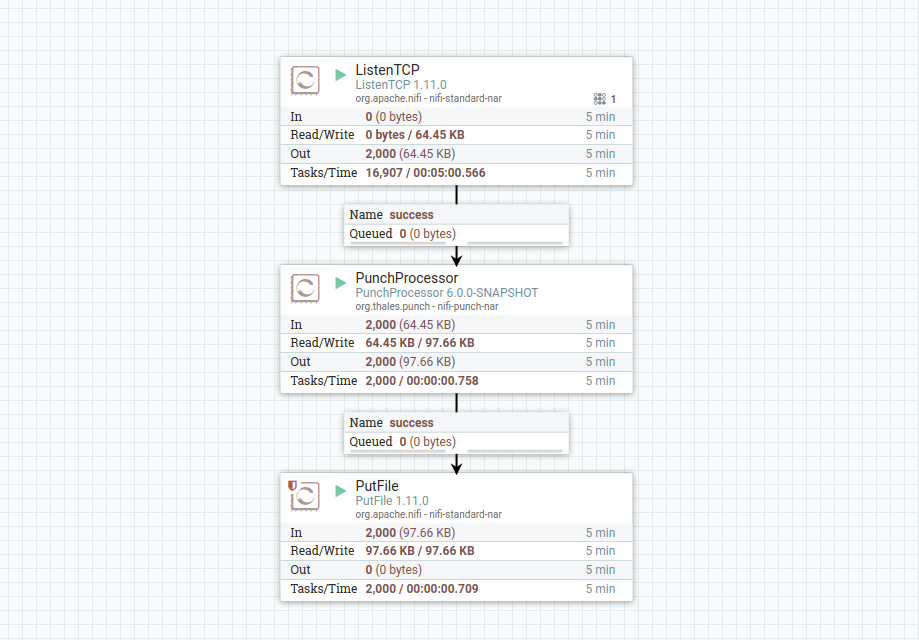
The processor is basically taking the input FlowFile, converts it into a punch tuple, runs a punchlet over this tuple and converts the output back to a FlowFile ready for transfer.
If you are familiar with the Punch, this is the equivalent of a Punch node in a (Storm|Spark|Punch) punchline. For those used to Nifi, it is just a new processor applying a punchlet to your FlowFile’s content.
This processor provides a bunch of useful features: specifying resources like grok patterns, loading resources from different sources, parsing multi-line input, transferring to multiple destinations… Let us take a quick overview of these abilities.
Resource configuration
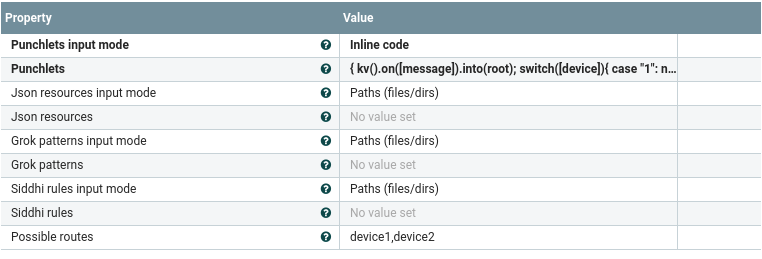
The PunchProcessor leverages the Nifi processor properties to provide resources. Looking at the property tab in the processor configuration window, you can see four different kinds of resources :
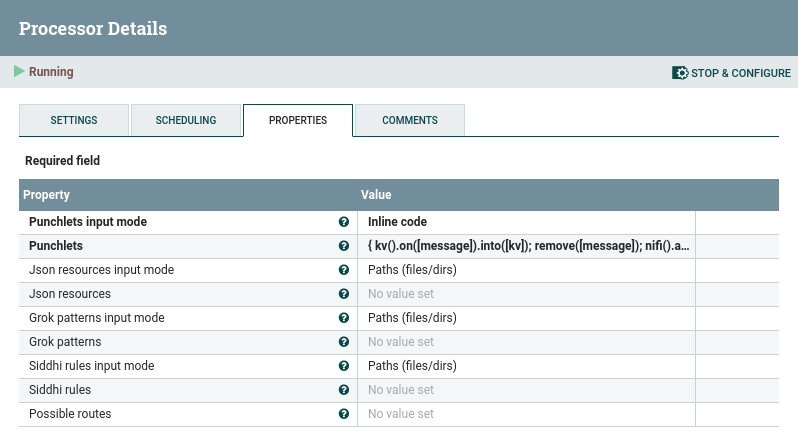
Route property will be presented later, in Output section.
On top of the required punchlets you want to apply to the input flowfile, you can also specify some Json resources, grok patterns or Siddhi rules. For each resource, three input modes are proposed :
- Inline Code: this mode allows you to provide the code of your resources directly in the property field.
- Paths (files/dirs): this mode allows to read the code of your resources from files. The values must be comma-separated filesystem paths.
If you provide a directory, all files contained in it will be read and considered as resources. If you provide a relative path, Nifi directory will be used as the root. For example:/etc/punch/input.punch,/etc/punch/enrichment.punch
- Http URL : this mode allows to fetch the code of your resources from an external API. A typical example is the Punch REST resource gateway. Values must be comma-separated urls. The response body will be read and considered as resource content.
This processor also takes advantage of Nifi’s validation system to check the resources availability and the correct punchlet compilation every time a property is modified. No need to restart the processor to recheck your inputs.
Input Format
When a FlowFile is received by the processor, its content is read and converted into a punch tuple following these rules :
- If the content is formatted as JSON, the tuple is the direct representation of this JSON.
- Otherwise, the tuple contains only a single field, called “message” and containing the content as String.
- If the content contains multiple lines, each line is extracted, converted to a tuple and processed separately from the others.
Output
After the punchlet has been applied, a new FlowFile is created, which content is the JSON representation of the resulting Tuple.
The PunchProcessor allows to dynamically create output Relationships. This is what the “Routes” property stands for. You can provide the routes you need, separated by commas, and the corresponding relationships will be created.
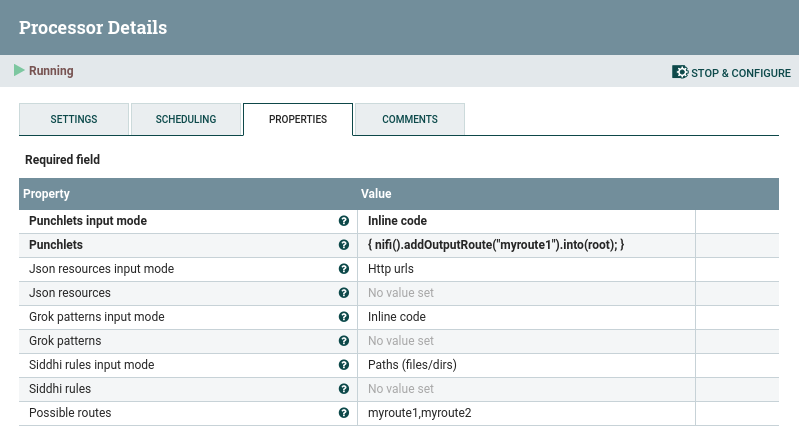
and the code basically transfer all incoming FlowFiles to “myroute1”.
To transfer the resulting FlowFile to the correct route, the punch language provides a dedicated operator. For example, you can write
nifi().addOutputRoute("myfirstroute").into(root);
If you do not set any route, the FlowFile will be transferred to the “default” route. If a non-existing route is provided, an exception is raised.
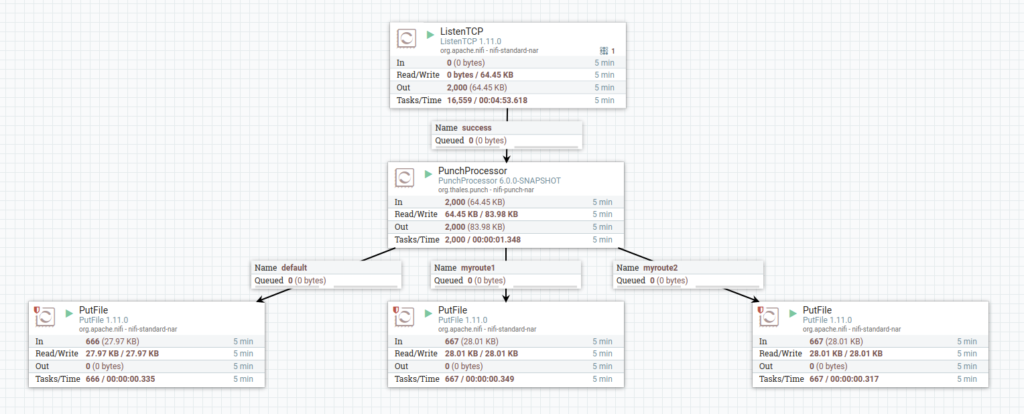
Complete Example
Say you receive lots of key-value logs at once.
timestamp=Feb 05 11:48:47 device=1 timestamp=Feb 05 11:51:36 device=2 timestamp=Feb 05 12:02:31 device=5 ...
You want to parse every line to get a JSON representing the key-value pairs. You also want to get logs from device 1 and 2 to go to specific destinations.
Here is the Nifi processor configuration :
Here is the complete punchlet:
{
kv().on([message]).into(root);
remove([message]);
switch([device]){
case "1":
nifi().addOutputRoute("device1").into(root);
break;
case "2":
nifi().addOutputRoute("device2").into(root);
break;
}
}
As you expect
- {“timestamp”:”Feb 05 11:48:47″,”device”:”1″} goes to device1 route
- {“timestamp”:”Feb 05 11:51:36″,”device”:”2″} goes to device2 route
- {“timestamp”:”Feb 05 12:02:31″,”device”:”5″} goes to the default route
Getting the PunchProcessor
As for now the PunchProcessor is not a built-in Nifi processor. You need to get the artifacts from the PunchPlatform Download Area. Two artifacts are provided.
- nifi-punch-nar-<punch-version>.nar : This is the processor nar. It includes the code to execute the PunchProcessor and the dependencies to compile a punchlet.
- nifi-punchlang-runtime-lib-<punch-version>.jar : This jar brings the required runtime dependencies to execute the punchlet once compiled.
Both these artifacts must be placed in your nifi ‘lib’ folder. (e.g. /data/opt/nifi/nifi-1.11.0/lib). Simply restart Nifi once done. The PunchProcessor will then be available in the list of processors. To insert one into your dataflow, simply drag and drog the processor icon into the working area and select the PunchProcessor in the provided list.
What’s Next
The punch keeps progressing and is now widely used in Thales. The Punch as a whole is a modular yet complete production-ready stack. It crunches all sorts of data: logs (of course), IOCs, scientific data.
As part of it, the punch language is extremely useful to avoid the configuration hell: better write a few lines of compact code than generating or writing tons of configuration files. With a few punch lines, you achieve powerful data transformation, filtering or enrichment. And this is useful for all sorts of data, not just logs.
This said the punch strategy is to share its assets. Punch parsers are shared among several projects. Having a punch Nifi processor is excellent news. It also favors various projects to embrace a common data normalization and taxonomy, and in particular the elastic common schema.
Stay tuned !


0 Comments