Tensorflow is a well-known and one of the most popular frameworks used for Deep Learning. It is an open-source library developed by Google and it is extremely useful to solve complex problems which require deep learning. It relies on making layers of data to learn, each layer identifying features from the inputs. Deeper is the network, more refined is the information on the data and it uses Python to provide a convenient front-end API for building applications while executing them in C++.
Keras is the official high-level API of TensorFlow. It allows building neural network architecture easily and intuitively. With a minimum of actions, you can create and train a neural network. Incorporating Keras and Tensorflow in PML simplifies even more the building of deep learning networks.

This article explains how to use Tensorflow and Keras in a PML pipeline and to present the generic nodes that have been developed for this purpose.
Walkthrough: Punch PySpark/Keras/TensorFlow setup
First, you need to check if you have Keras and TensorFlow in the version of PML. Normally, after the version 5.3.0 of the punch, you should have them installed. Check the list of modules :
pip list
And look for Keras and TensorFlow. If they are not installed, you need to modify the requirements.txt file in punchplatform-standalone-x.x.x/pp-pyspark. Add manually the versions of keras and tensorflow you want, like :
keras==2.2.4
tensorflow==1.14.0
Then, do the same thing for the requirements.txt file in punchplatform-standalone-x.x.x/pp-pyspark/downloads.
To apply the change, you need to set up the punchplatform pyspark. Go in the pp-pyspark location and execute :
make dev
This will create a virtualenv directory called « .venv », then, you can activate it :
source .venv/bin/activate
Build the nodes with
make build
(you will have to rerun this command if you modify or add new nodes)
Now, you can run PML pipelines with the following command :
spark-submit --master spark://localhost:7077 --jars downloads/elasticsearch-hadoop-*.jar --py-files dist/nodes.zip --conf "spark.driver.extraJavaOptions=-Dlog4j.configuration=file:conf/log4j.properties" dist/punchplatform-pyspark.py --job examples/test_keras.pml
Walkthrough: Deep learning with Tensorflow and Keras
Now that you have Keras and TensorFlow installed in your Python, they can be used for deep learning applications.
Let’s look at a classical example of deep learning training with the MNIST dataset. It includes 60000 pictures of 28×28 pixels in black and white, labeled between 0 and 9. The goal of this dataset is to train models to recognize the numbers between 0 and 9.

This dataset has already been processed so we can focus on the training and testing part in PML.
The simplest TensorFlow python script to handle this dataset is the following, which loads the MNIST dataset, defines a CNN model in tensorflow, trains it and evaluates it on a testing set.
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(512, activation=tf.nn.relu),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
model.evaluate(x_test, y_test)Walkthrough: TensorFlow/Keras PML pipeline
We can execute PML pipelines that include deep learning easily. For that, generic nodes have been incorporated in the list of available nodes in pp-pyspark for the different steps in the training, validation, and testing. Let’s apply these nodes to the MNIST example.
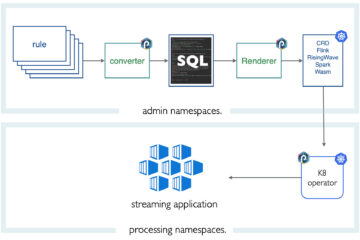
The structure of a basic PML pipeline for MNIST is the following :
In the orange blocks, you can see the generic nodes used for the main steps in the training and testing of the model. The different nodes are presented further in the article. The blue block is the custom node for the processing of MNIST data which must be custom since it is specific to the problem. It simply loads the MNIST dataset and converts it to training and testing sets. The green block allows you to save your trained model in order to reuse it on new data, in another pipeline for example.

Then, you can output predictions or information from your pipeline and your model to elastic for instance or incorporate in another pipeline.
The PML pipeline mnist_example.pml performs the training and the predictions of the MNIST dataset and output the model. In the streams, you have x_train, y_train, x_test, y_test, and model. Run it with the following command :
spark-submit --master spark://localhost:7077 --jars downloads/elasticsearch-hadoop-*.jar --py-files dist/nodes.zip --conf "spark.driver.extraJavaOptions=-Dlog4j.configuration=file:conf/log4j.properties" dist/punchplatform-pyspark.py --job examples/mnist_example.pml
Walkthrough : Predictive maintenance using Timeseries
Another example of the utilization of TensorFlow and Keras is the predictive maintenance using time series. You can easily adapt the generic nodes to this kind of case. Let’s consider time series of 3000 timesteps, each one having a label of 0 or 1, 1 meaning there was an incident. We want to predict these incidents in new time series.
The structure of the training and the predicting pipelines are the same as for the MNIST example, only the data processing node has to be changed. We can combine them into one pipeline :
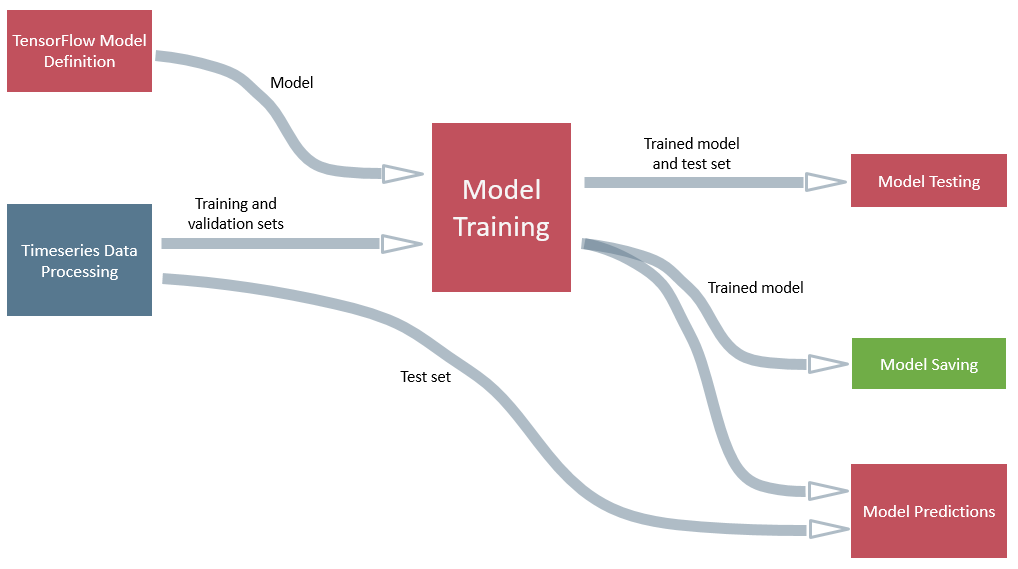
Yet, you still need to choose the parameters for the definition and training of the model, of course.
The PML pipeline test_keras.pml will perform all these steps, from data processing to predictions, going through training and testing.
spark-submit --master spark://localhost:7077 --jars downloads/elasticsearch-hadoop-*.jar --py-files dist/nodes.zip --conf "spark.driver.extraJavaOptions=-Dlog4j.configuration=file:conf/log4j.properties" dist/punchplatform-pyspark.py --job examples/test_keras.pml
It accesses the timeseries stored in examples/data and stores a trained model at the same location, that can be used in another pipeline to only make predictions.
As you can see, the nodes for deep learning in PML are pretty reusable. They are described further in the next section.
Generic Keras and Tensorflow nodes
To simplify the building, training, testing, and prediction of a deep learning model, several generic nodes have been created in the pyspark setup of PML. Here is a brief description of the main ones :
- tf_model_definition.py : this node allows you to define the structure of the model you want to train as you would do with TensorFlow. It returns the untrained model. Since you need to construct your model, you will have to change the node itself to add the layers you want. Then, do not forget to use the command make build to build again the nodes.
- keras_model_definition.py : same thing but with Keras
- keras_model_show.py : displays the structure of the model
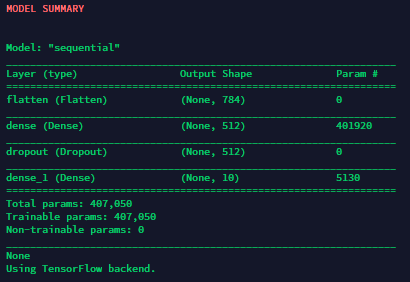
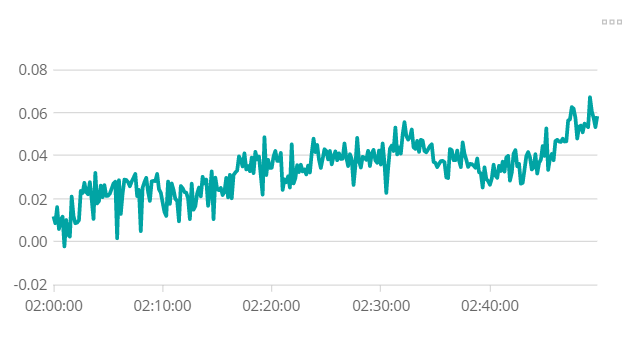
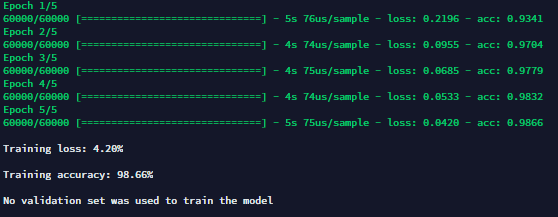
- tf_model_training.py : performs the training of the model thanks to the training and validation set you have to provide. Takes x_train, y_train and model as inputs and returns a trained model in output. A list of parameters corresponding to the compile and fit parameters of Keras is included and can be defined in the pipeline. This node displays the progress in the training as well as loss and accuracy values :
- keras_model_save.py : saves the trained model in a h5 file.
- keras_model_test.py : takes x_test, y_test and the trained model as inputs. Returns different information of the testing such as the test loss and accuracy. You can choose the metrics you want to display.
- keras_model_prediction : applies a trained model to a dataset, either a saved one or a one trained in the pipeline.
These nodes have been created during the two previous examples, so not all features and parameters have been included yet. But you can always copy the nodes and adapt them for your case.
For now, you have to modify the model definition node when you want to create a new architecture since it is specific to each problem. Also, the data processing before the entry must be performed in another node or the data must be preprocessed before applying the pipeline.
It is now up to you to create deep learning pipelines with these different Keras and TensorFlow nodes.