Successfully deploying and maintaining machine learning applications is, to us (punch team), still a real challenge. We have read many papers and blogs introducing great new technologies to tackle mlops issues. We still find the whole process far from being simple and mastered on industrial, mission critical and/or on-premise use cases.
According to Gartner 80 % of artificial intelligence projects simply fail. Most do not go farther than proof-of-concept. Why is that so ? First, these applications are data centric, and dealing with data is difficult:
- large quantities of data require large amount of resources (compute/storage) and complex technologies
- security is a must : role based access control, protecting data integrity and confidentiality at rest or in movement
- data is important, it is not an option to lose some (despite failures)
- the produced results are critical, it is not an option either to produce false results (despite failures)
- real-time applications add low-latency and high-throughput requirements in the equation
With machine learning models deployed in there new issues pop up: ML model deployment, performance monitoring, update and rollback, traceability all require a well-design process and tooling.
Probably the greatest barrier is simply to hire trained and skilled engineers. Recruiting kubernetes-ready/cloud-ready/FaaS-ready/mlflow-ready data scientists or engineers is difficult and costly. (By the way if you are one, please send us your resume).
This blog aims at clarifying these issues and provide our own (modest) on-premise strategy. It seems to us there are still common misunderstandings of the whole mlops process, of the role of the different actors, and in the required good practices to make it simpler and more effective.
MLOPS Explained
Here is a quick recap of the MLOPS process. Three essential stages are identified : ML, DEV and OP.
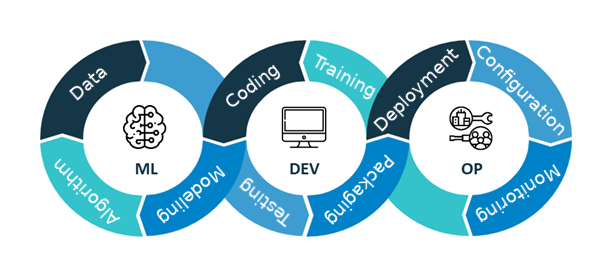
Figure 1. Description of the mlops stages.
- ML
- Understand the business problem
- Model it in terms of data processes
- Identify the various available data sources
- DEV
- Code, Train, Test and Package the models
- OP
- Deploy the models for execution
- Monitor the model performance
- Deal with its lifecycle
Simple and easy. Of course we want to achieve this in a way to code the minimum (hence leverage a low-code solution), and succeed in deploying these models as part of a secured and scalable solution.
Here are some interesting questions :
- Is there a way to benefit from generic and agnostic prediction pipelines ? Or will we be condemned to code ad-hoc applications for every use case ?
- How to periodically evaluate the deployed models and prevent data drift ?
- How to deploy a new model version without service interruption ?
In this blog we explain how we assembled a few technologies to end up with an as-simple-as-possible and as-complete-as-possible solution. To make it concrete and pragmatic, all the code is available in this GitHub repo.
What You Need
Our technological zoo consists of Jupyter, MLFlow, S3 (we use Minio), Postgres, Spark (PySpark), on top of the databases where our data resides : Elasticsearch, Clickhouse, Kafka or S3. All these run on Kubernetes.
Our solution needs to perform predictions from a given AI model and monitor each deployed models. This could be implemented as batch processing jobs using Spark. Better we can use the punch platform punchline mechanism (or something similar). Punchlines lets you create Spark jobs by configuration, combining many pre-implemented nodes. You only plug in your logic in the middle using SQL statements, by providing your own nodes, or spark user defined functions. In short it is a function-as-a-service architecture powered by Spark. The two benefits are first to code little (or not at all in some case), and second it promotes nodes and functions reuse as we will see later on.
Additionnally, we choose to use MLFlow, “an open source platform to manage the ML lifecycle, including experimentation, reproducibility, deployment, and a central model registry“. MLFlow can be seen as a common interface between Data Engineers and Data Scientists. Data Scientists develop and store their packaged models in MLFlow and expose them through the model registry. In turn Data Engineers can then fetch and deploy the models. As the packaging and serving parts are ensure by MLFlow, deployment is completely agnostic.
Remote storage and relational database are required by MLFlow to respectively store artifacts and associated metada. Moreover it will unlock the registry feature wich is crucial in our solution as we will also see later in this blog.
Solution
Now that we have introduced the technologies, let us show the big picture and how each component interact with each others.
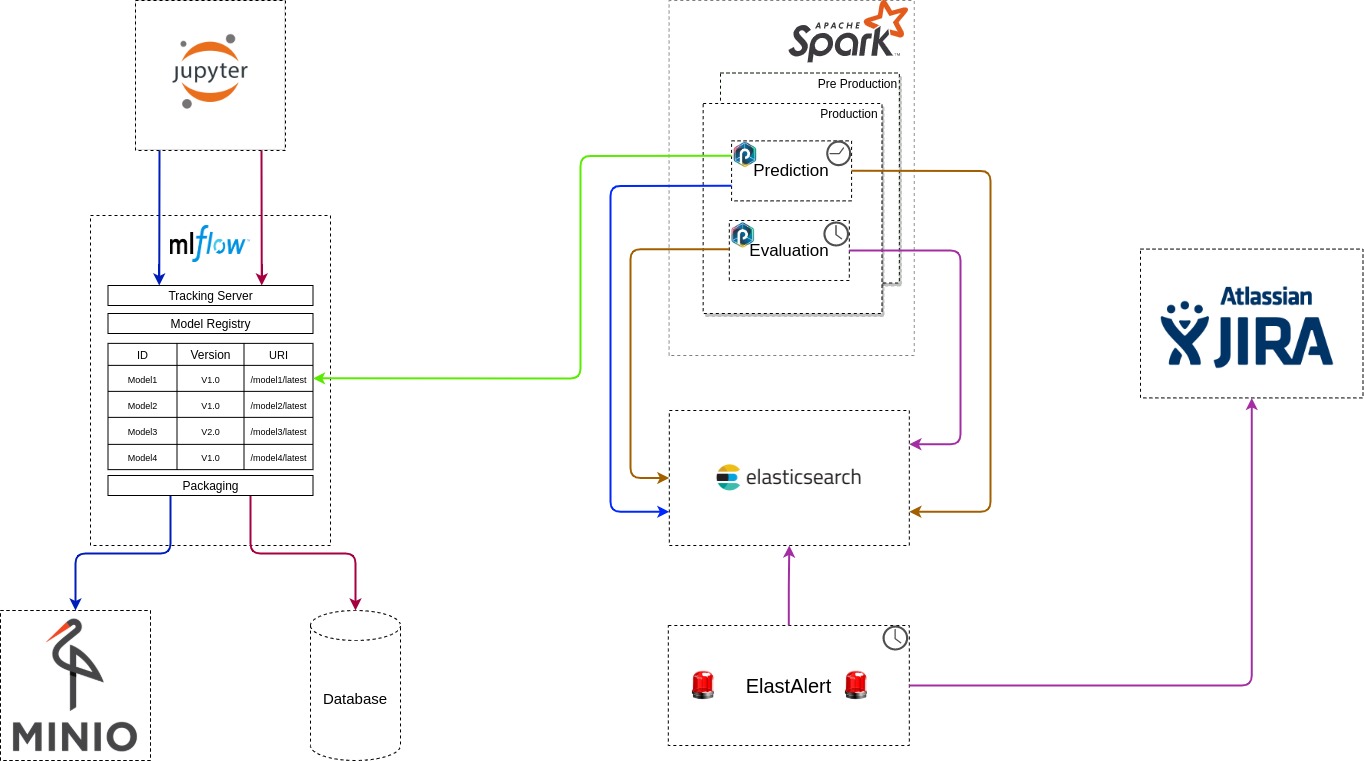
Figure 2. End-to-end mlops architecture.
Here is the complete story step by step:
- Once a given model is trained and locally tested, it will be historized thanks to the mlflow Tracking Server feature.
- In background, when a model is stored, an artifact with some extra metadata is respectively saved in an object storage and a relational database thanks to the mlflow Packaging feature.
- An historized model is registered to the registry under a unique identifier. Each model is reachable through a unique URI.
- Periodically, a prediction pipeline loads a given model from its URI and use it to perform predictions on a production dataset. Predictions are saved in a database.
- Periodically an evaluation pipeline compares these predictions with the true values. The computed scores are also saved in a database.
- Periodically yet another job checks the validity of the model and triggers an alert if it is deprecated.
Punchlines
There are a number of ways to implement the different jobs we just described. To avoid coding ad hoc applications we leverage the punch spark pipelines called sparklines.
Side note: these are now referred to as sparklines, just because the punch also supports flinklines, stormlines etc .. hopefully you get the idea if your are familiar with the spark, flink or storm data processing engines.
Two sparklines are used to handle prediction and evaluation tasks. By combining input/output connectors and specific configurable AI nodes we wanted to build generic pipelines, let us detail them.
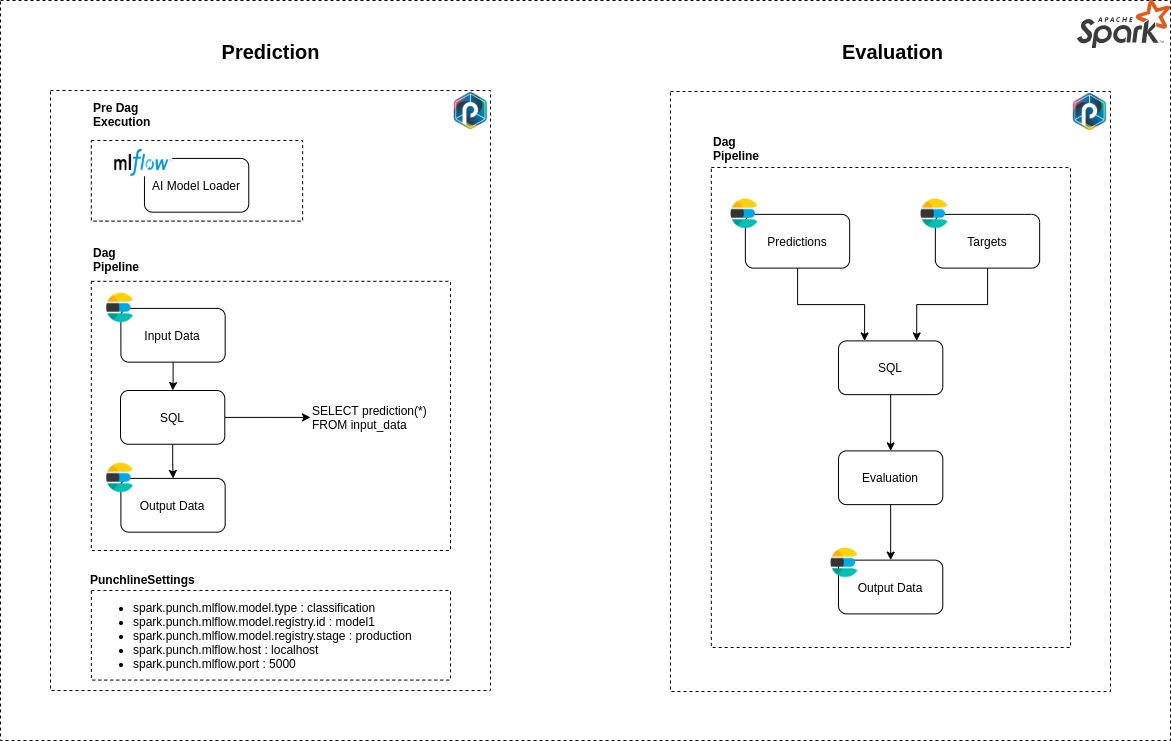
Figure 3. Predictions and evaluation pipelines.
Prediction Pipeline
- Firstly, the AI Model Loader node will query MLflow in order to load in memory a model from to the provided URI. Once the model loaded, a pandas UDF prediction function is built and registered to the Spark Context.
- Secondly, data is loaded from ElasticSearch into a Spark DataFrame object.
-
Next, the prediction function is invoked through a SQL query and applied to the input data.
-
The generated predictions are saved in ElasticSearch
The sparkline can be configured to fetch any model reachable from MLflow. If you have a look at the GitHub project you will find in the sparkline settings section a model ID, stage, and mlflow server.
Evaluation Pipeline
-
Two inputs data are required :
- The predictions generated by the AI model
- The true values
-
Once the data are loaded, many evaluation scores are used to test the deployed model.
- All evaluation scores will be saved in ElasticSearch.
The evaluation node will infer on the evaluation_python_modules and evaluation_python_class parameters in order to load the corresponding python classes and use them to compare dataset_predicted_target_column and dataset_real_target_column columns.
settings: {
evaluation_python_modules : ["sklearn.metrics", "sklearn.metrics"]
evaluation_python_class : ["mean_absolute_error", "mean_squared_error"]
dataset_predicted_target_column : "prediction"
dataset_real_target_column : "real"
dataset_decoration_column : ["creation_timestamp"]
}
Scalable Solution
Prediction and Evaluation pipelines are built on top of sparklines. That basically means that each runs in a Kubernetes native spark job. Hence prediction and evaluation jobs can be distributed over a cluster should you need more resources to crunch in more data. In addition, the prediction sparkline uses a Spark Pandas UDF as prediction function. Such function leverages vectorized operations that can take advantage of SIMD architecture. According to databricks, vectorized operations “can increase performance up to 100x compared to row-at-a-time Python UDFs”.
Multi Layer Test
We will now setup a test cycle composed of three stages in order to validate the relevance of our model:
- Development : Locally test on a test dataset sample. The candidate model is registered to MLFLOW.
- Pre Production : Compute predictions from production data. These predictions are however not stored in production database. The evaluation pipeline is run to validate these predictions.
- Production : if ok, we switch from staging to production. The predictions are now stored in production database and visible to users.
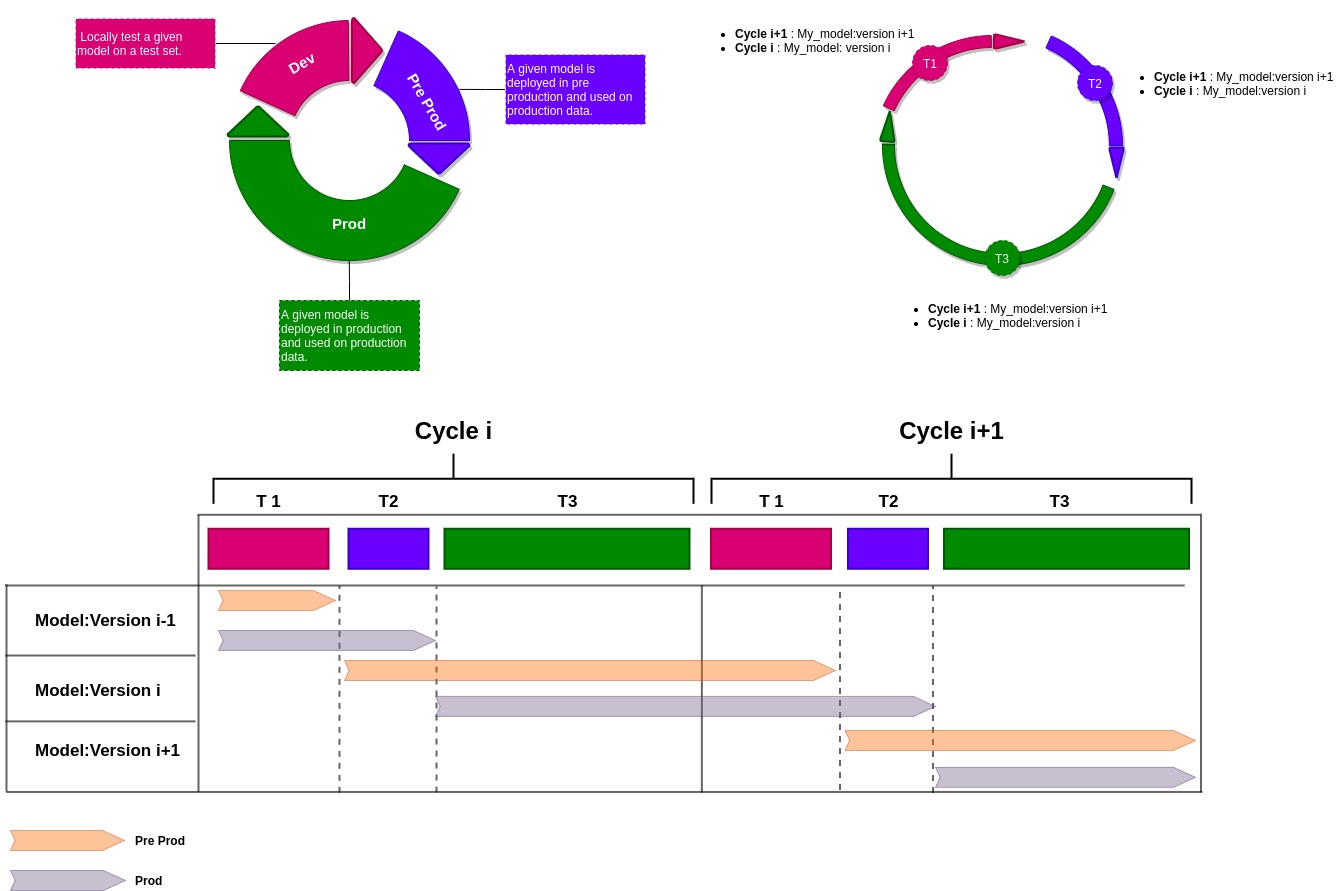
Figure 4. End-to-end AI models tests to prevent data drift.
As we can see, at time T2, the production has one version delay compared to the pre production. At time T1 the production and pre production has one version delay compared to the development.
How to switch a model from one layer to another?
Once a model is registered in the registry, it is possible to label it with a stage. For example None, Staging or Production. Thanks to the MLFlow API, we can then query the latest version of a model for a couple (stage, ID).
Two instances for the prediction and evaluation sparklines are required. One instance for the pre-production and the other for the production. Pre-production and production sparklines will respectively load the latest version with respectively stage Staging or Production.
To switch a model from pre-production to production, we simply need to alter its stage from Staging to Production. This operation can be done manually from the MLFlow UI or automated in a python code snippet by using the MLFlow API.
Easy to deploy & Easy to maintain
Prediction and evaluation pipelines are generics. They cover many use cases and can be ajustable to the needs.
Under the hood MLFlow historized a scikit learn pipeline. That is, a chain of Transformers and Estimators. Deployment can be very quick because the scikit learn pipeline will be automatically converted into a Spark Pandas UDF and invoked through an SQL query.
Thanks to the MLFlow Registry, a URI refers the latest version of each exposed models. If a new version is pushed, then the corresponding URI will be updated to this new version. Considering that the AI models are reloaded for each prediction job runs. Pushing a new model version has no impact on the prediction pipeline.
WARNING : Aggregation functions cannot be packaged in a scikit learn pipeline. They have to be manually added to the prediction pipeline.
Conclusion
Let us recap what we achieved. Our main goal was to provide the simplest yet complete MLOPS on-premise solution. Thanks to MLFlow, punch and Kubernetes; we could implement and assemble all the required concepts and features in order to handle AI models life cycle from end to end.
Better, we ended up with two generic pipelines ready to be reused for other industrial prediction and evaluation use case. Because these leverage the punch low-code approach, these pipelines, called sparklines, are easy to understand, easy to maintain, and easy to run. Leveraging Spark is key as it makes us capable of industrialising scalable solutions.
A side note: the latest punch release is now a native Kubernetes solution. Sparklines are run in a Spark3 framework itself leveraging Kubernetes. This is to say using the punch dramatically eases the use of Spark. This topics is rich, stay tuned for a dedicated blog on this.
Our three layers of testing ensure model performance before deployment to production. Periodic evaluation helps to detect data drift therefore a deprecated model. Finally, updating models is completely transparent and automated in production : the prediction pipeline always infers the last known version.
What Next ?
The solution we described is based on two asumptions:
- We have no strong real time or low latency expectations, it means that we can use batch processing for the predicion steps.
- AI models are small and can fit in memory.
If one of the two assumption is not met, new issues appear and we need additionnal technical solutions.
For instance, a prediction pipeline running in a stream context will compute outdated results since a new model has been pushed but not reloaded. The same kind of problem appears when AI models are served through an end point REST API.
We need a solution to detect any change on a model (restore/update) and trigger the reloading. These actions must be done without service interruption and avoid as much as possible the use of outdated models.
These are our current topics of investigations. Thanks for reading our blog.



0 Comments